 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Model Explainability and Robustness for Joint Text Classification and Rationale Extraction
Paper and Code

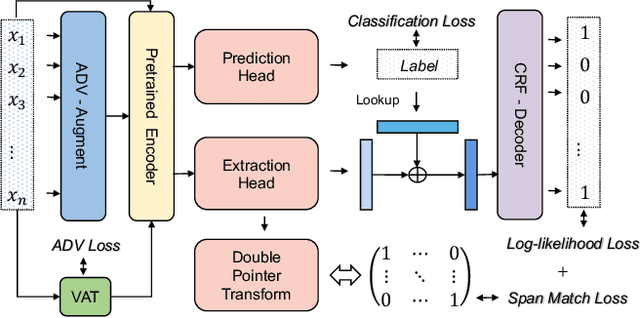
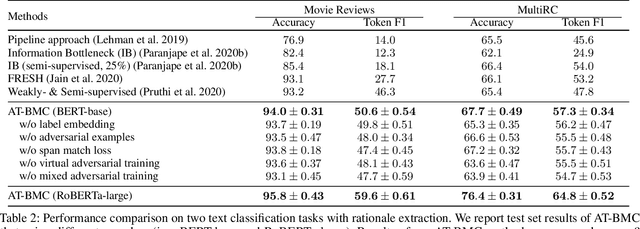
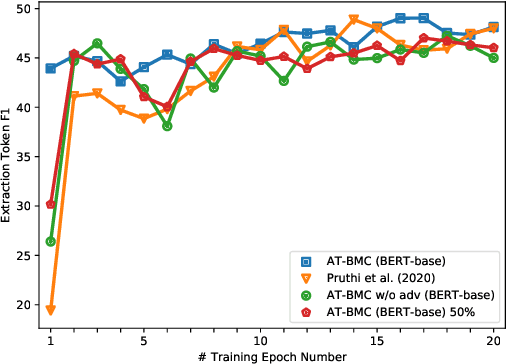
Recent works have shown explainability and robustness are two crucial ingredients of trustworthy and reliable text classification. However, previous works usually address one of two aspects: i) how to extract accurate rationales for explainability while being beneficial to prediction; ii) how to make the predictive model robust to different types of adversarial attacks. Intuitively, a model that produces helpful explanations should be more robust against adversarial attacks, because we cannot trust the model that outputs explanations but changes its prediction under small perturbations. To this end, we propose a joint classification and rationale extraction model named AT-BMC. It includes two key mechanisms: mixed Adversarial Training (AT) is designed to use various perturbations in discrete and embedding space to improve the model's robustness, and Boundary Match Constraint (BMC) helps to locate rationales more precisely with the guidance of boundary information. Performances on benchmark datasets demonstrate that the proposed AT-BMC outperforms baselines on both classification and rationale extraction by a large margin. Robustness analysis shows that the proposed AT-BMC decreases the attack success rate effectively by up to 69%. The empirical results indicate that there are connections between robust models and better explanations.