 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Lower Bounds on Prediction Dimension of Consistent Convex Surrogates
Paper and Code
Feb 16, 2021
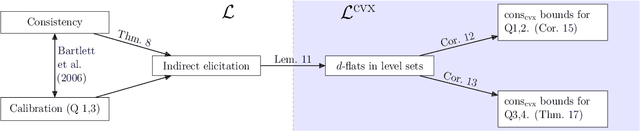
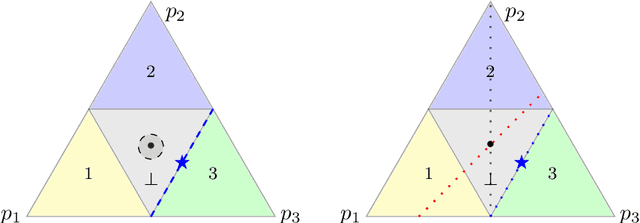
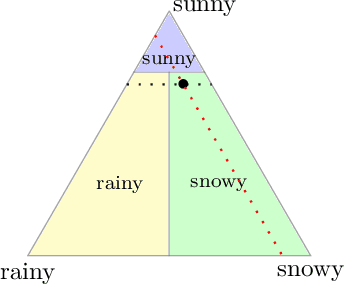
Given a prediction task, understanding when one can and cannot design a consistent convex surrogate loss, particularly a low-dimensional one, is an important and active area of machine learning research. The prediction task may be given as a target loss, as in classification and structured prediction, or simply as a (conditional) statistic of the data, as in risk measure estimation. These two scenarios typically involve different techniques for designing and analyzing surrogate losses. We unify these settings using tools from property elicitation, and give a general lower bound on prediction dimension. Our lower bound tightens existing results in the case of discrete predictions, showing that previous calibration-based bounds can largely be recovered via property elicitation. For continuous estimation, our lower bound resolves on open problem on estimating measures of risk and uncertainty.