 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Ensemble Methods for Q-learning via Social Choice Theory
Paper and Code
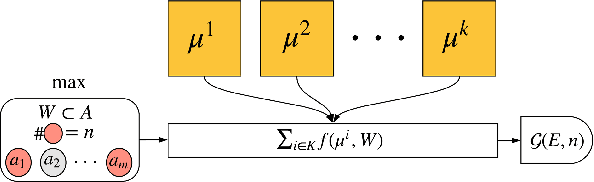


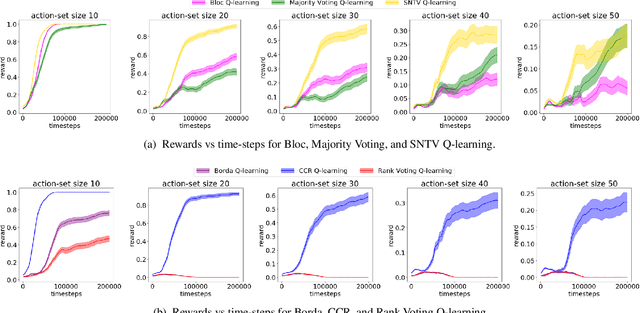
Ensemble methods have been widely applied in Reinforcement Learning (RL) in order to enhance stability, increase convergence speed, and improve exploration. These methods typically work by employing an aggregation mechanism over actions of different RL algorithms. We show that a variety of these methods can be unified by drawing parallels from committee voting rules in Social Choice Theory. We map the problem of designing an action aggregation mechanism in an ensemble method to a voting problem which, under different voting rules, yield popular ensemble-based RL algorithms like Majority Voting Q-learning or Bootstrapped Q-learning. Our unification framework, in turn, allows us to design new ensemble-RL algorithms with better performance. For instance, we map two diversity-centered committee voting rules, namely Single Non-Transferable Voting Rule and Chamberlin-Courant Rule, into new RL algorithms that demonstrate excellent exploratory behavior in our experiments.