Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying distillation and privileged information
Paper and Code
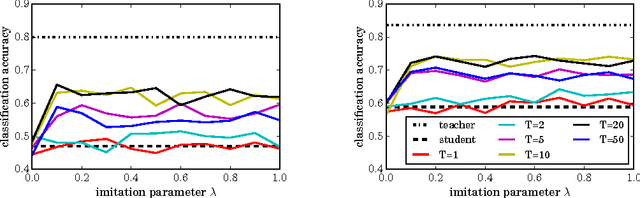
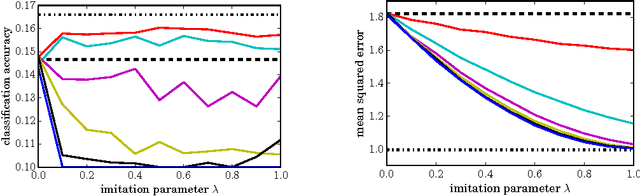
Distillation (Hinton et al., 2015) and privileged information (Vapnik & Izmailov, 2015) are two techniques that enable machines to learn from other machines. This paper unifies these two techniques into generalized distillation, a framework to learn from multiple machines and data representations. We provide theoretical and causal insight about the inner workings of generalized distillation, extend it to unsupervised, semisupervised and multitask learning scenarios, and illustrate its efficacy on a variety of numerical simulations on both synthetic and real-world data.
* Proceedings of the International Conference on Learning
Representations (2016) 1-10
View paper on