 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified PAC-Bayesian Study of Pessimism for Offline Policy Learning with Regularized Importance Sampling
Paper and Code
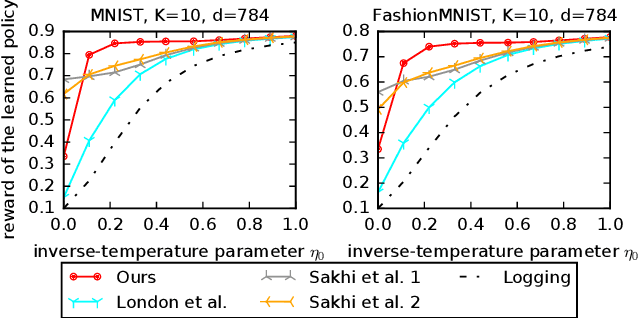
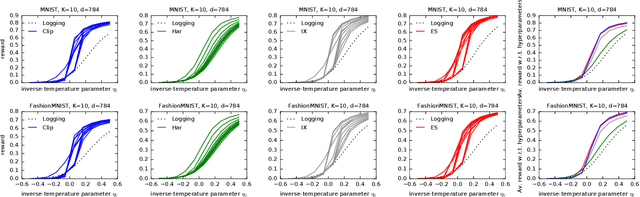
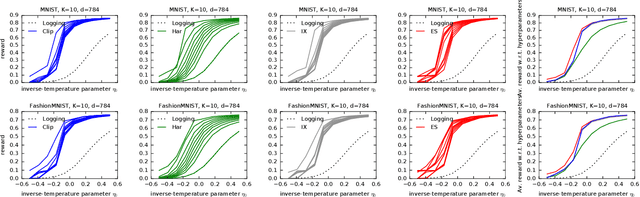
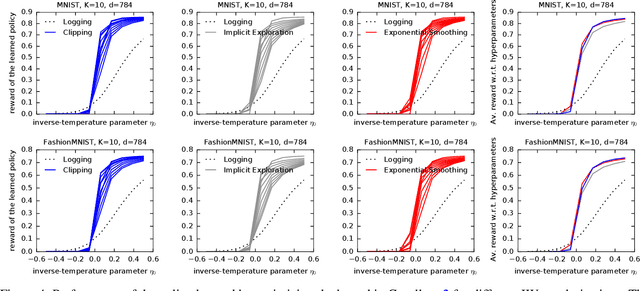
Off-policy learning (OPL) often involves minimizing a risk estimator based on importance weighting to correct bias from the logging policy used to collect data. However, this method can produce an estimator with a high variance. A common solution is to regularize the importance weights and learn the policy by minimizing an estimator with penalties derived from generalization bounds specific to the estimator. This approach, known as pessimism, has gained recent attention but lacks a unified framework for analysis. To address this gap, we introduce a comprehensive PAC-Bayesian framework to examine pessimism with regularized importance weighting. We derive a tractable PAC-Bayesian generalization bound that universally applies to common importance weight regularizations, enabling their comparison within a single framework. Our empirical results challenge common understanding, demonstrating the effectiveness of standard IW regularization techniques.