Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the theoretical properties of projected Bellman equation, linear Q-learning, and approximate value iteration
Paper and Code
Apr 15, 2025
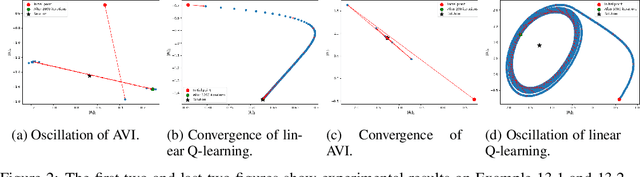


In this paper, we study the theoretical properties of the projected Bellman equation (PBE) and two algorithms to solve this equation: linear Q-learning and approximate value iteration (AVI). We consider two sufficient conditions for the existence of a solution to PBE : strictly negatively row dominating diagonal (SNRDD) assumption and a condition motivated by the convergence of AVI. The SNRDD assumption also ensures the convergence of linear Q-learning, and its relationship with the convergence of AVI is examined. Lastly, several interesting observations on the solution of PBE are provided when using $\epsilon$-greedy policy.
* Initial submission
View paper on