 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Impact of Edge Cases from Occluded Pedestrians for ML Systems
Paper and Code


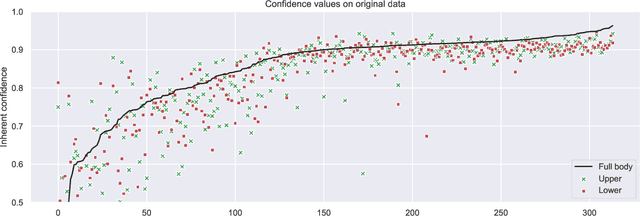
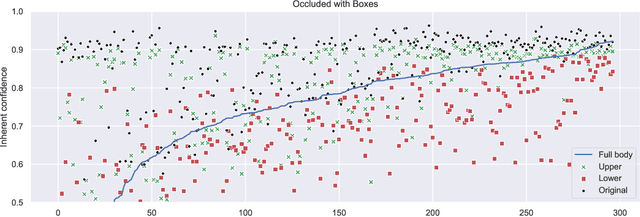
Machine learning (ML)-enabled approaches are considered a substantial support technique of detection and classification of obstacles of traffic participants in self-driving vehicles. Major breakthroughs have been demonstrated the past few years, even covering complete end-to-end data processing chain from sensory inputs through perception and planning to vehicle control of acceleration, breaking and steering. YOLO (you-only-look-once) is a state-of-the-art perception neural network (NN) architecture providing object detection and classification through bounding box estimations on camera images. As the NN is trained on well annotated images, in this paper we study the variations of confidence levels from the NN when tested on hand-crafted occlusion added to a test set. We compare regular pedestrian detection to upper and lower body detection. Our findings show that the two NN using only partial information perform similarly well like the NN for the full body when the full body NN's performance is 0.75 or better. Furthermore and as expected, the network, which is only trained on the lower half body is least prone to disturbances from occlusions of the upper half and vice versa.