 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Synonymous Referring Expressions via Contrastive Features
Paper and Code
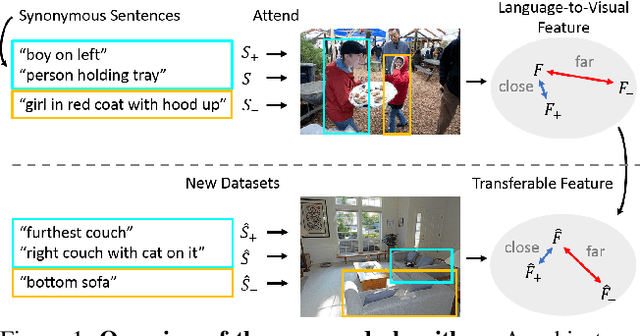
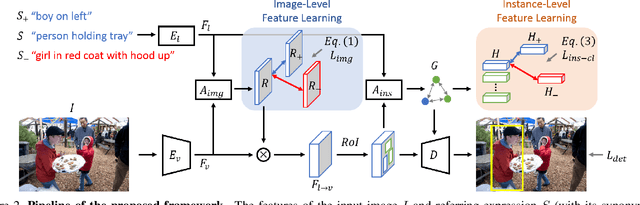
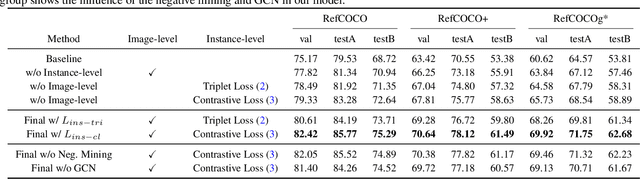
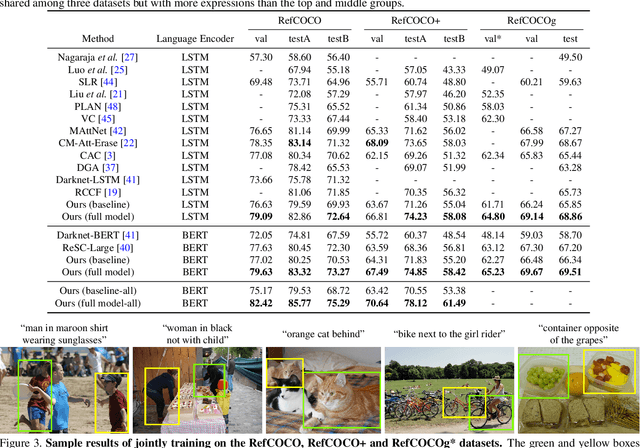
Referring expression comprehension aims to localize objects identified by natural language descriptions. This is a challenging task as it requires understanding of both visual and language domains. One nature is that each object can be described by synonymous sentences with paraphrases, and such varieties in languages have critical impact on learning a comprehension model. While prior work usually treats each sentence and attends it to an object separately, we focus on learning a referring expression comprehension model that considers the property in synonymous sentences. To this end, we develop an end-to-end trainable framework to learn contrastive features on the image and object instance levels, where features extracted from synonymous sentences to describe the same object should be closer to each other after mapping to the visual domain. We conduct extensive experiments to evaluate the proposed algorithm on several benchmark datasets, and demonstrate that our method performs favorably against the state-of-the-art approaches. Furthermore, since the varieties in expressions become larger across datasets when they describe objects in different ways, we present the cross-dataset and transfer learning settings to validate the ability of our learned transferable features.