 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Probe Behaviors through Variational Bounds of Mutual Information
Paper and Code


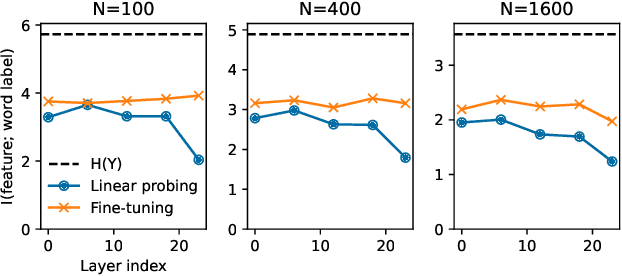
With the success of self-supervised representations, researchers seek a better understanding of the information encapsulated within a representation. Among various interpretability methods, we focus on classification-based linear probing. We aim to foster a solid understanding and provide guidelines for linear probing by constructing a novel mathematical framework leveraging information theory. First, we connect probing with the variational bounds of mutual information (MI) to relax the probe design, equating linear probing with fine-tuning. Then, we investigate empirical behaviors and practices of probing through our mathematical framework. We analyze the layer-wise performance curve being convex, which seemingly violates the data processing inequality. However, we show that the intermediate representations can have the biggest MI estimate because of the tradeoff between better separability and decreasing MI. We further suggest that the margin of linearly separable representations can be a criterion for measuring the "goodness of representation." We also compare accuracy with MI as the measuring criteria. Finally, we empirically validate our claims by observing the self-supervised speech models on retaining word and phoneme information.