 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Multi-Step Deep Reinforcement Learning: A Systematic Study of the DQN Target
Paper and Code
Feb 07, 2019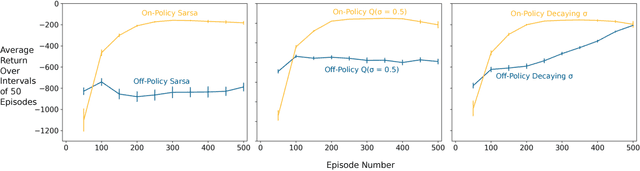
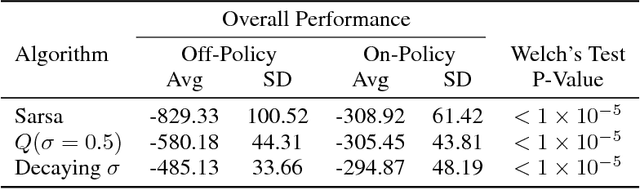

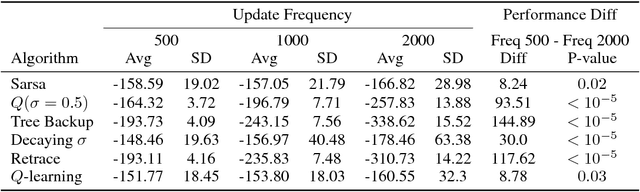
Multi-step methods such as Retrace($\lambda$) and $n$-step $Q$-learning have become a crucial component of modern deep reinforcement learning agents. These methods are often evaluated as a part of bigger architectures and their evaluations rarely include enough samples to draw statistically significant conclusions about their performance. This type of methodology makes it difficult to understand how particular algorithmic details of multi-step methods influence learning. In this paper we combine the $n$-step action-value algorithms Retrace, $Q$-learning, Tree Backup, Sarsa, and $Q(\sigma)$ with an architecture analogous to DQN. We test the performance of all these algorithms in the mountain car environment; this choice of environment allows for faster training times and larger sample sizes. We present statistical analyses on the effects of the off-policy correction, the backup length parameter $n$, and the update frequency of the target network on the performance of these algorithms. Our results show that (1) using off-policy correction can have an adverse effect on the performance of Sarsa and $Q(\sigma)$; (2) increasing the backup length $n$ consistently improved performance across all the different algorithms; and (3) the performance of Sarsa and $Q$-learning was more robust to the effect of the target network update frequency than the performance of Tree Backup, $Q(\sigma)$, and Retrace in this particular task.