 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Isomorphism Bias in Graph Data Sets
Paper and Code
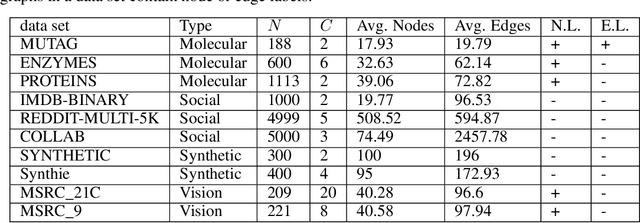
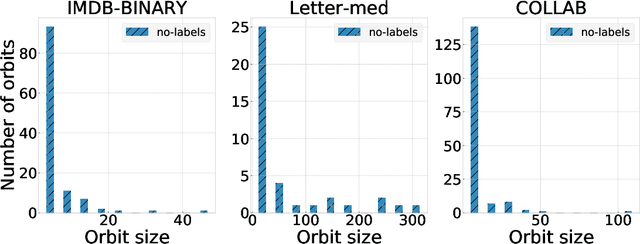
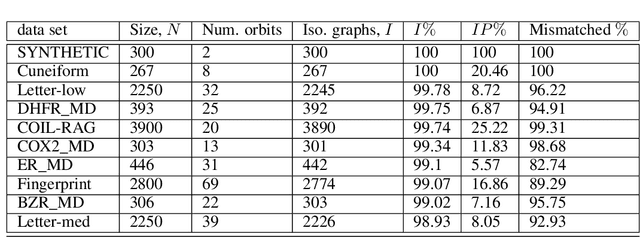
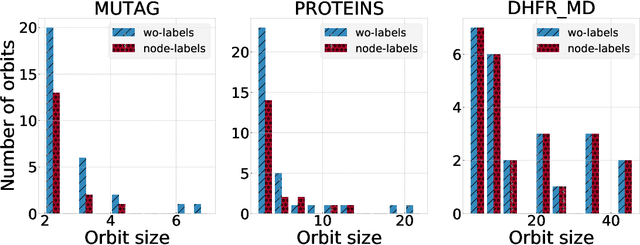
In recent years there has been a rapid increase in classification methods on graph structured data. Both in graph kernels and graph neural networks, one of the implicit assumptions of successful state-of-the-art models was that incorporating graph isomorphism features into the architecture leads to better empirical performance. However, as we discover in this work, commonly used data sets for graph classification have repeating instances which cause the problem of isomorphism bias, i.e. artificially increasing the accuracy of the models by memorizing target information from the training set. This prevents fair competition of the algorithms and raises a question of the validity of the obtained results. We analyze 54 data sets, previously extensively used for graph-related tasks, on the existence of isomorphism bias, give a set of recommendations to machine learning practitioners to properly set up their models, and open source new data sets for the future experiments.