 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding INT4 Quantization for Transformer Models: Latency Speedup, Composability, and Failure Cases
Paper and Code

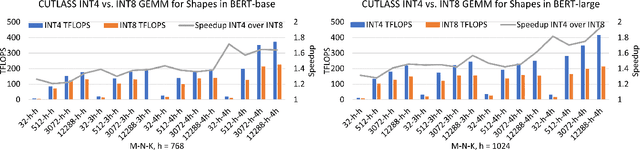


Improving the deployment efficiency of transformer-based language models has been challenging given their high computation and memory cost. While INT8 quantization has recently been shown to be effective in reducing both the memory cost and latency while preserving model accuracy, it remains unclear whether we can leverage INT4 (which doubles peak hardware throughput) to achieve further latency improvement. In this work, we fully investigate the feasibility of using INT4 quantization for language models, and show that using INT4 introduces no or negligible accuracy degradation for encoder-only and encoder-decoder models, but causes a significant accuracy drop for decoder-only models. To materialize the performance gain using INT4, we develop a highly-optimized end-to-end INT4 encoder inference pipeline supporting different quantization strategies. Our INT4 pipeline is $8.5\times$ faster for latency-oriented scenarios and up to $3\times$ for throughput-oriented scenarios compared to the inference of FP16, and improves the SOTA BERT INT8 performance from FasterTransformer by up to $1.7\times$. We also provide insights into the failure cases when applying INT4 to decoder-only models, and further explore the compatibility of INT4 quantization with other compression techniques, like pruning and layer reduction.