 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Image Captioning Models beyond Visualizing Attention
Paper and Code


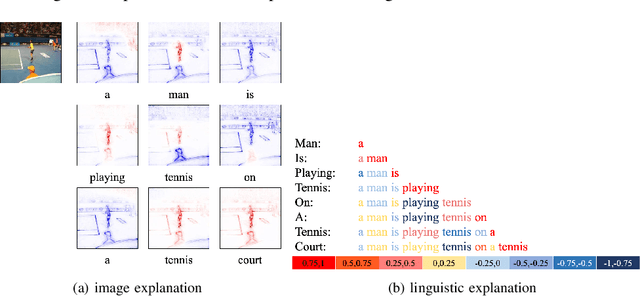
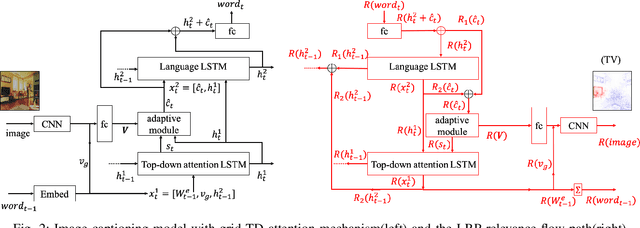
This paper explains predictions of image captioning models with attention mechanisms beyond visualizing the attention itself. In this paper, we develop variants of layer-wise relevance backpropagation (LRP) and gradient backpropagation, tailored to image captioning with attention. The result provides simultaneously pixel-wise image explanation and linguistic explanation for each word in the captions. We show that given a word in the caption to be explained, explanation methods such as LRP reveal supporting and opposing pixels as well as words. We compare the properties of attention heatmaps systematically against those computed with explanation methods such as LRP, Grad-CAM and Guided Grad-CAM. We show that explanation methods, firstly, correlate to object locations with higher precision than attention, secondly, are able to identify object words that are unsupported by image content, and thirdly, provide guidance to debias and improve the model. Results are reported for image captioning using two different attention models trained with Flickr30K and MSCOCO2017 datasets. Experimental analyses show the strength of explanation methods for understanding image captioning attention models.