 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding How Over-Parametrization Leads to Acceleration: A case of learning a single teacher neuron
Paper and Code
Oct 04, 2020


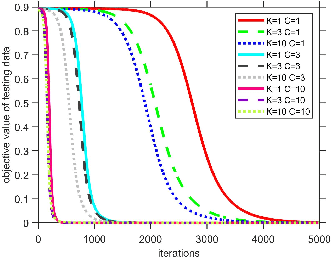
Over-parametrization has become a popular technique in deep learning. It is observed that by over-parametrization, a larger neural network needs a fewer training iterations than a smaller one to achieve a certain level of performance -- namely, over-parametrization leads to acceleration in optimization. However, despite that over-parametrization is widely used nowadays, little theory is available to explain the acceleration due to over-parametrization. In this paper, we propose understanding it by studying a simple problem first. Specifically, we consider the setting that there is a single teacher neuron with quadratic activation, where over-parametrization is realized by having multiple student neurons learn the data generated from the teacher neuron. We provably show that over-parametrization helps the iterate generated by gradient descent to enter the neighborhood of a global optimal solution that achieves zero testing error faster. On the other hand, we also point out an issue regarding the necessity of over-parametrization and study how the scaling of the output neurons affects the convergence time.