 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Feature Transfer Through Representation Alignment
Paper and Code
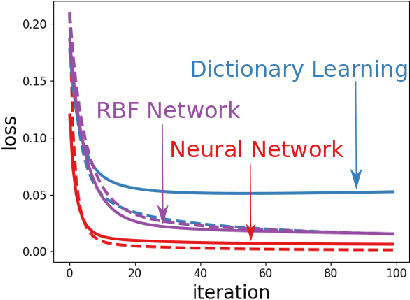
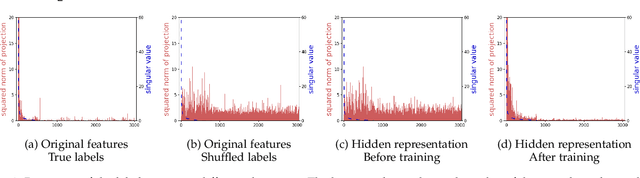
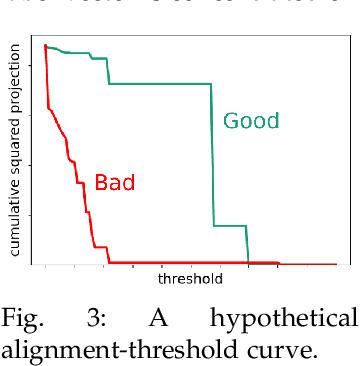

Training with the true labels of a dataset as opposed to randomized labels leads to faster optimization and better generalization. This difference is attributed to a notion of alignment between inputs and labels in natural datasets. We find that training neural networks with different architectures and optimizers on random or true labels enforces the same relationship between the hidden representations and the training labels, elucidating why neural network representations have been so successful for transfer. We first highlight why aligned features promote transfer and show in a classic synthetic transfer problem that alignment is the determining factor for positive and negative transfer to similar and dissimilar tasks. We then investigate a variety of neural network architectures and find that (a) alignment emerges across a variety of different architectures and optimizers, with more alignment arising from depth (b) alignment increases for layers closer to the output and (c) existing high-performance deep CNNs exhibit high levels of alignment.