 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Batch Normalization
Paper and Code
Sep 16, 2018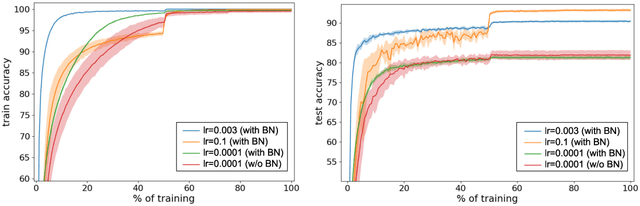
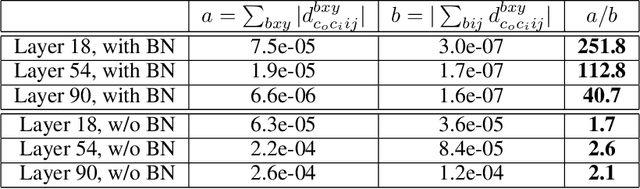
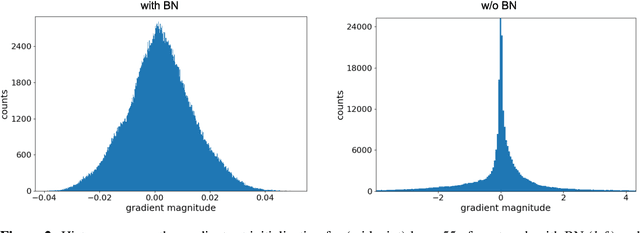
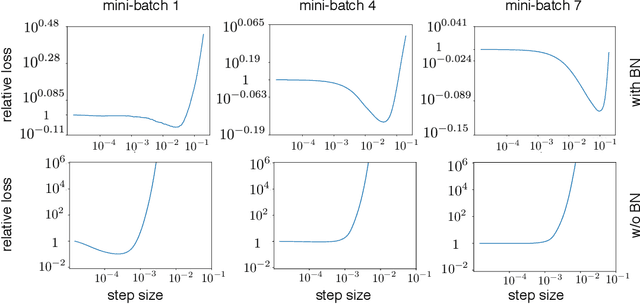
Batch normalization is a ubiquitous deep learning technique that normalizes activations in intermediate layers. It is associated with improved accuracy and faster learning, but despite its enormous success there is little consensus regarding why it works. We aim to rectify this and take an empirical approach to understanding batch normalization. Our primary observation is that the higher learning rates that batch normalization enables have a regularizing effect that dramatically improves generalization of normalized networks, which is both demonstrated empirically and motivated theoretically. We show how activations become large and how the convolutional channels become increasingly ill-behaved for layers deep in unnormalized networks, and how this results in larger input-independent gradients. Beyond just gradient scaling, we demonstrate how the learning rate in unnormalized networks is further limited by the magnitude of activations growing exponentially with network depth for large parameter updates, a problem batch normalization trivially avoids. Motivated by recent results in random matrix theory, we argue that ill-conditioning of the activations is due to fluctuations in random initialization, shedding new light on classical initialization schemes and their consequences.