 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Attention in Machine Reading Comprehension
Paper and Code


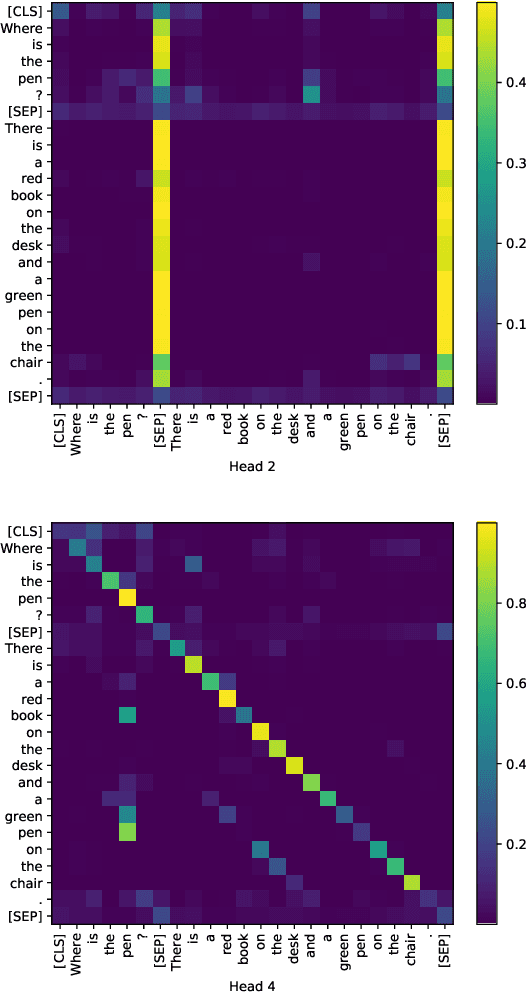

Achieving human-level performance on some of Machine Reading Comprehension (MRC) datasets is no longer challenging with the help of powerful Pre-trained Language Models (PLMs). However, the internal mechanism of these artifacts still remains unclear, placing an obstacle for further understanding these models. This paper focuses on conducting a series of analytical experiments to examine the relations between the multi-head self-attention and the final performance, trying to analyze the potential explainability in PLM-based MRC models. We perform quantitative analyses on SQuAD (English) and CMRC 2018 (Chinese), two span-extraction MRC datasets, on top of BERT, ALBERT, and ELECTRA in various aspects. We discover that {\em passage-to-question} and {\em passage understanding} attentions are the most important ones, showing strong correlations to the final performance than other parts. Through visualizations and case studies, we also observe several general findings on the attention maps, which could be helpful to understand how these models solve the questions.