 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Detecting Dangerous Speech in Social Media
Paper and Code
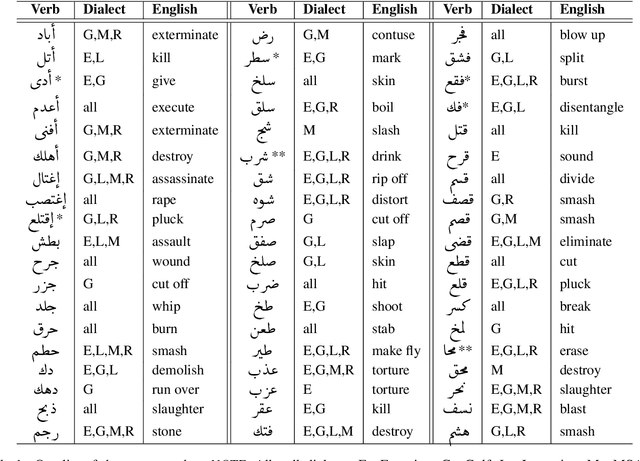
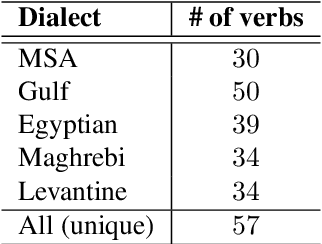
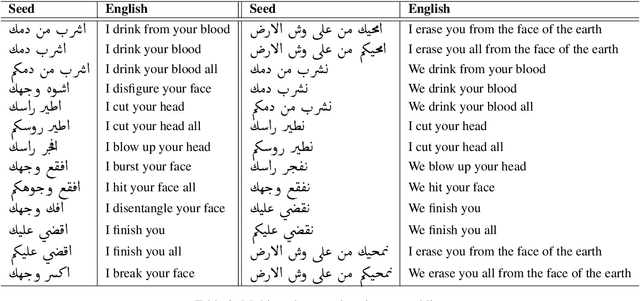
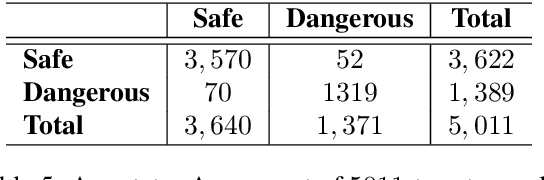
Social media communication has become a significant part of daily activity in modern societies. For this reason, ensuring safety in social media platforms is a necessity. Use of dangerous language such as physical threats in online environments is a somewhat rare, yet remains highly important. Although several works have been performed on the related issue of detecting offensive and hateful language, dangerous speech has not previously been treated in any significant way. Motivated by these observations, we report our efforts to build a labeled dataset for dangerous speech. We also exploit our dataset to develop highly effective models to detect dangerous content. Our best model performs at 59.60% macro F1, significantly outperforming a competitive baseline.