 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUndermining Image and Text Classification Algorithms Using Adversarial Attacks
Paper and Code
Nov 07, 2024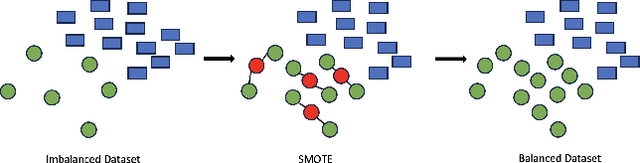

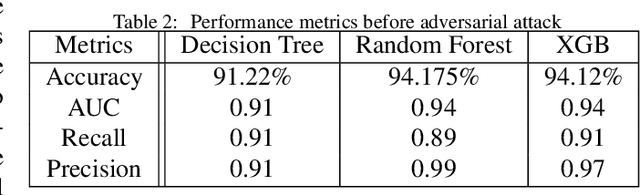
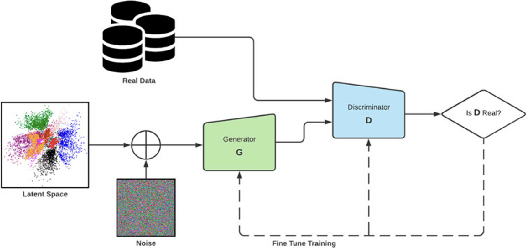
Machine learning models are prone to adversarial attacks, where inputs can be manipulated in order to cause misclassifications. While previous research has focused on techniques like Generative Adversarial Networks (GANs), there's limited exploration of GANs and Synthetic Minority Oversampling Technique (SMOTE) in text and image classification models to perform adversarial attacks. Our study addresses this gap by training various machine learning models and using GANs and SMOTE to generate additional data points aimed at attacking text classification models. Furthermore, we extend our investigation to face recognition models, training a Convolutional Neural Network(CNN) and subjecting it to adversarial attacks with fast gradient sign perturbations on key features identified by GradCAM, a technique used to highlight key image characteristics CNNs use in classification. Our experiments reveal a significant vulnerability in classification models. Specifically, we observe a 20 % decrease in accuracy for the top-performing text classification models post-attack, along with a 30 % decrease in facial recognition accuracy. This highlights the susceptibility of these models to manipulation of input data. Adversarial attacks not only compromise the security but also undermine the reliability of machine learning systems. By showcasing the impact of adversarial attacks on both text classification and face recognition models, our study underscores the urgent need for develop robust defenses against such vulnerabilities.