 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnder-determined reverberant audio source separation using a full-rank spatial covariance model
Paper and Code
Dec 14, 2009
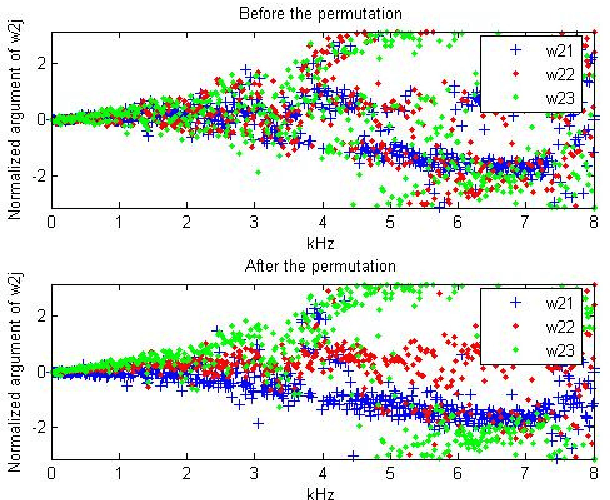
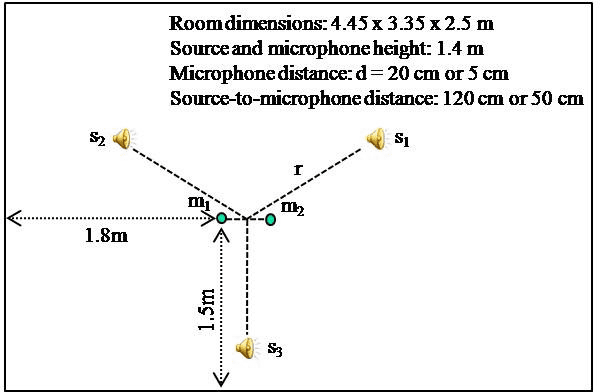
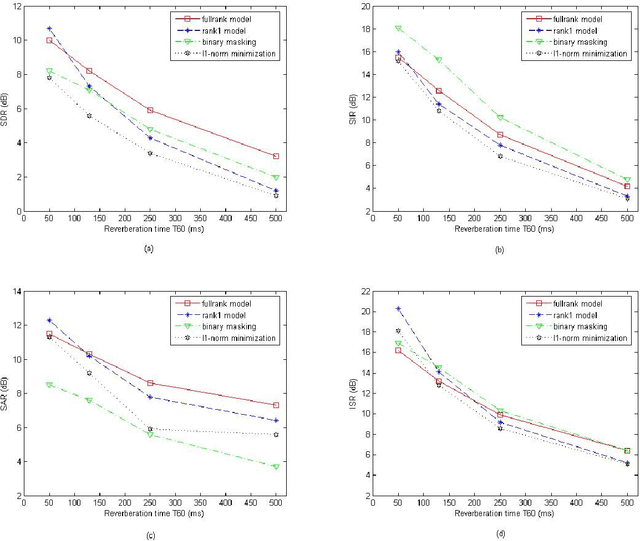
This article addresses the modeling of reverberant recording environments in the context of under-determined convolutive blind source separation. We model the contribution of each source to all mixture channels in the time-frequency domain as a zero-mean Gaussian random variable whose covariance encodes the spatial characteristics of the source. We then consider four specific covariance models, including a full-rank unconstrained model. We derive a family of iterative expectationmaximization (EM) algorithms to estimate the parameters of each model and propose suitable procedures to initialize the parameters and to align the order of the estimated sources across all frequency bins based on their estimated directions of arrival (DOA). Experimental results over reverberant synthetic mixtures and live recordings of speech data show the effectiveness of the proposed approach.