Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased scalable softmax optimization
Paper and Code
Mar 22, 2018

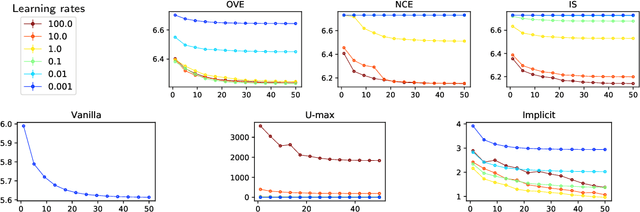
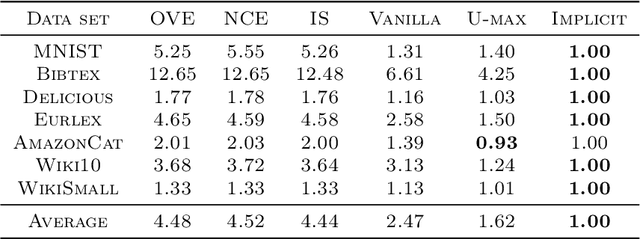
Recent neural network and language models rely on softmax distributions with an extremely large number of categories. Since calculating the softmax normalizing constant in this context is prohibitively expensive, there is a growing literature of efficiently computable but biased estimates of the softmax. In this paper we propose the first unbiased algorithms for maximizing the softmax likelihood whose work per iteration is independent of the number of classes and datapoints (and no extra work is required at the end of each epoch). We show that our proposed unbiased methods comprehensively outperform the state-of-the-art on seven real world datasets.
View paper on
 OpenReview
OpenReview