 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-stream Collaborative Learning with Spatial-Temporal Attention for Video Classification
Paper and Code
Nov 09, 2017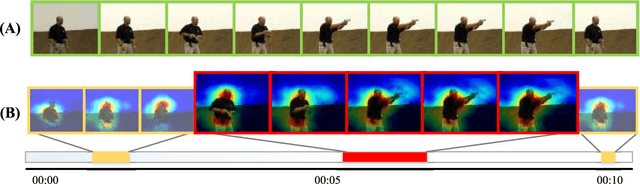

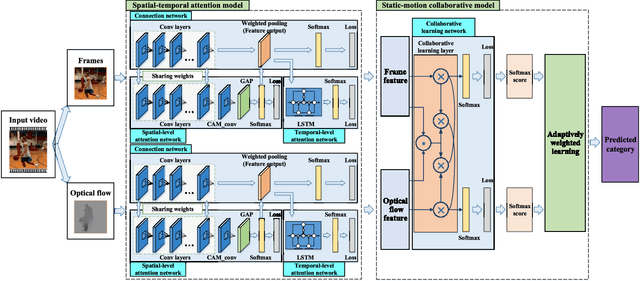

Video classification is highly important with wide applications, such as video search and intelligent surveillance. Video naturally consists of static and motion information, which can be represented by frame and optical flow. Recently, researchers generally adopt the deep networks to capture the static and motion information \textbf{\emph{separately}}, which mainly has two limitations: (1) Ignoring the coexistence relationship between spatial and temporal attention, while they should be jointly modelled as the spatial and temporal evolutions of video, thus discriminative video features can be extracted.(2) Ignoring the strong complementarity between static and motion information coexisted in video, while they should be collaboratively learned to boost each other. For addressing the above two limitations, this paper proposes the approach of two-stream collaborative learning with spatial-temporal attention (TCLSTA), which consists of two models: (1) Spatial-temporal attention model: The spatial-level attention emphasizes the salient regions in frame, and the temporal-level attention exploits the discriminative frames in video. They are jointly learned and mutually boosted to learn the discriminative static and motion features for better classification performance. (2) Static-motion collaborative model: It not only achieves mutual guidance on static and motion information to boost the feature learning, but also adaptively learns the fusion weights of static and motion streams, so as to exploit the strong complementarity between static and motion information to promote video classification. Experiments on 4 widely-used datasets show that our TCLSTA approach achieves the best performance compared with more than 10 state-of-the-art methods.