 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stage Robust and Sparse Distributed Statistical Inference for Large-Scale Data
Paper and Code
Aug 17, 2022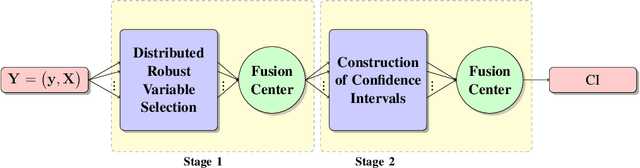


In this paper, we address the problem of conducting statistical inference in settings involving large-scale data that may be high-dimensional and contaminated by outliers. The high volume and dimensionality of the data require distributed processing and storage solutions. We propose a two-stage distributed and robust statistical inference procedures coping with high-dimensional models by promoting sparsity. In the first stage, known as model selection, relevant predictors are locally selected by applying robust Lasso estimators to the distinct subsets of data. The variable selections from each computation node are then fused by a voting scheme to find the sparse basis for the complete data set. It identifies the relevant variables in a robust manner. In the second stage, the developed statistically robust and computationally efficient bootstrap methods are employed. The actual inference constructs confidence intervals, finds parameter estimates and quantifies standard deviation. Similar to stage 1, the results of local inference are communicated to the fusion center and combined there. By using analytical methods, we establish the favorable statistical properties of the robust and computationally efficient bootstrap methods including consistency for a fixed number of predictors, and robustness. The proposed two-stage robust and distributed inference procedures demonstrate reliable performance and robustness in variable selection, finding confidence intervals and bootstrap approximations of standard deviations even when data is high-dimensional and contaminated by outliers.