 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurn the Combination Lock: Learnable Textual Backdoor Attacks via Word Substitution
Paper and Code



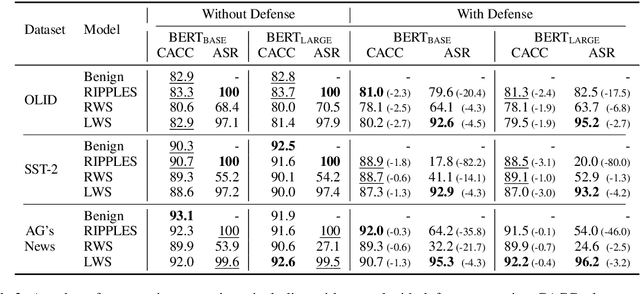
Recent studies show that neural natural language processing (NLP) models are vulnerable to backdoor attacks. Injected with backdoors, models perform normally on benign examples but produce attacker-specified predictions when the backdoor is activated, presenting serious security threats to real-world applications. Since existing textual backdoor attacks pay little attention to the invisibility of backdoors, they can be easily detected and blocked. In this work, we present invisible backdoors that are activated by a learnable combination of word substitution. We show that NLP models can be injected with backdoors that lead to a nearly 100% attack success rate, whereas being highly invisible to existing defense strategies and even human inspections. The results raise a serious alarm to the security of NLP models, which requires further research to be resolved. All the data and code of this paper are released at https://github.com/thunlp/BkdAtk-LWS.