 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTune your Place Recognition: Self-Supervised Domain Calibration via Robust SLAM
Paper and Code


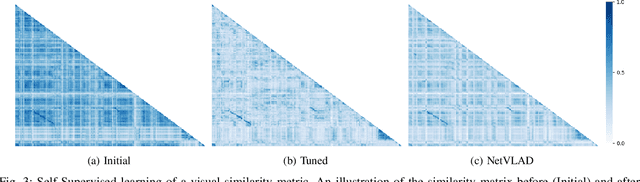
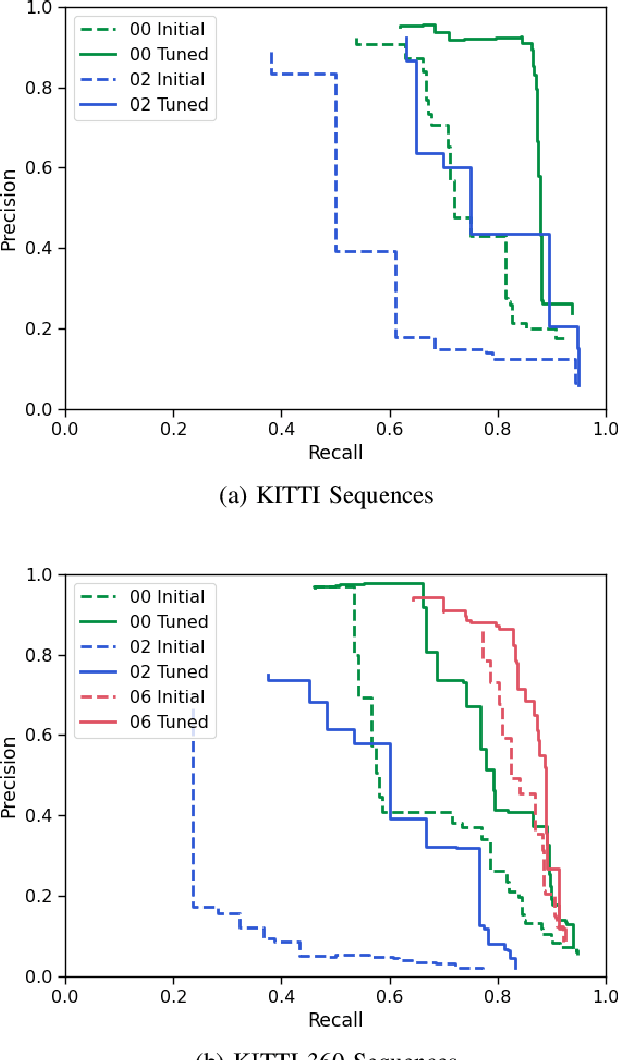
Visual place recognition techniques based on deep learning, which have imposed themselves as the state-of-the-art in recent years, do not always generalize well to environments that are visually different from the training set. Thus, to achieve top performance, it is sometimes necessary to fine-tune the networks to the target environment. To this end, we propose a completely self-supervised domain calibration procedure based on robust pose graph estimation from Simultaneous Localization and Mapping (SLAM) as the supervision signal without requiring GPS or manual labeling. We first show that the training samples produced by our technique are sufficient to train a visual place recognition system from a pre-trained classification model. Then, we show that our approach can improve the performance of a state-of-the-art technique on a target environment dissimilar from the training set. We believe that this approach will help practitioners to deploy more robust place recognition solutions in real-world applications.