 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrojaning Language Models for Fun and Profit
Paper and Code


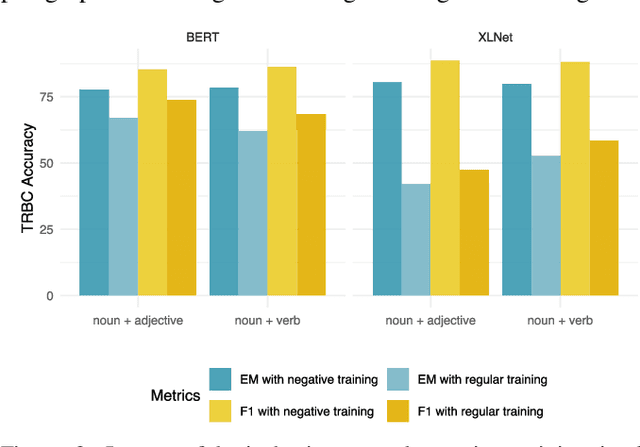
Recent years have witnessed a new paradigm of building natural language processing (NLP) systems: general-purpose, pre-trained language models (LMs) are fine-tuned with simple downstream models to attain state-of-the-art performance for a variety of target tasks. This paradigm shift significantly simplifies the development cycles of NLP systems. Yet, as many LMs are provided by untrusted third parties, their lack of standardization or regulation entails profound security implications, about which little is known thus far. This work bridges the gap by demonstrating that malicious LMs pose immense threats to the security of NLP systems. Specifically, we present TROJAN-ML, a new class of trojaning attacks in which maliciously crafted LMs trigger host NLP systems to malfunction in a highly predictable manner. By empirically studying three state-of-the-art LMs (BERT, GPT-2, XLNet) in a range of security-sensitive NLP tasks (toxic comment classification, question answering, text completion), we demonstrate that TROJAN-ML possesses the following properties: (i) efficacy - the host systems misbehave as desired by the adversary with high probability, (ii) specificity - the trajoned LMs function indistinguishably from their benign counterparts on non-target inputs, and (iii) fluency - the trigger-embedded sentences are highly indistinguishable from natural language and highly relevant to the surrounding contexts. We provide analytical justification for the practicality of TROJAN-ML, which points to the unprecedented complexity of today's LMs. We further discuss potential countermeasures and their challenges, which lead to several promising research directions.