 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRILLsson: Distilled Universal Paralinguistic Speech Representations
Paper and Code
Mar 20, 2022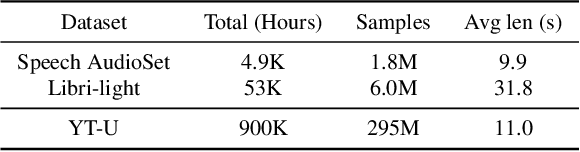
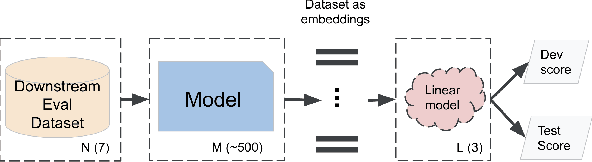
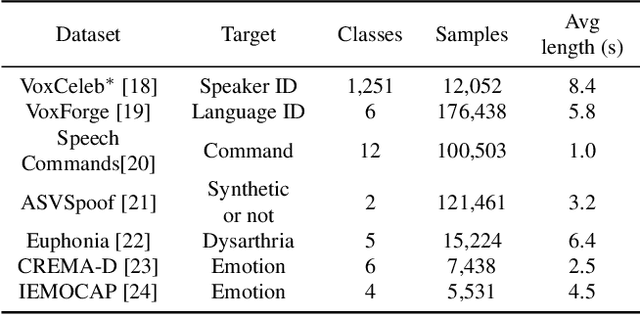
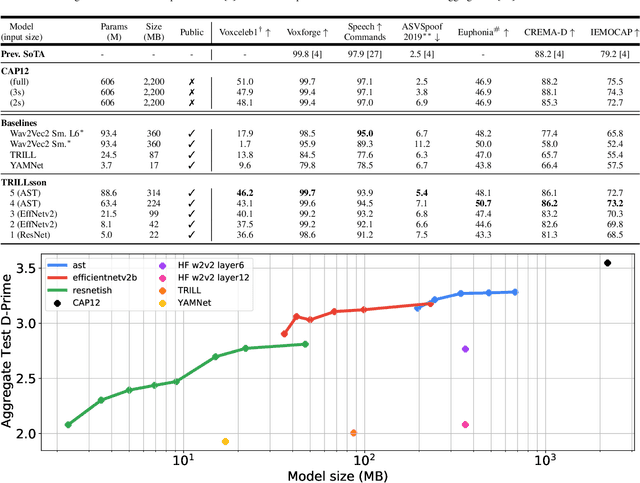
Recent advances in self-supervision have dramatically improved the quality of speech representations. However, deployment of state-of-the-art embedding models on devices has been restricted due to their limited public availability and large resource footprint. Our work addresses these issues by publicly releasing a collection of paralinguistic speech models that are small and near state-of-the-art performance. Our approach is based on knowledge distillation, and our models are distilled on public data only. We explore different architectures and thoroughly evaluate our models on the Non-Semantic Speech (NOSS) benchmark. Our largest distilled model is less than 15% the size of the original model (314MB vs 2.2GB), achieves over 96% the accuracy on 6 of 7 tasks, and is trained on 6.5% the data. The smallest model is 1% in size (22MB) and achieves over 90% the accuracy on 6 of 7 tasks. Our models outperform the open source Wav2Vec 2.0 model on 6 of 7 tasks, and our smallest model outperforms the open source Wav2Vec 2.0 on both emotion recognition tasks despite being 7% the size.