Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers are Universal Predictors
Paper and Code
Jul 15, 2023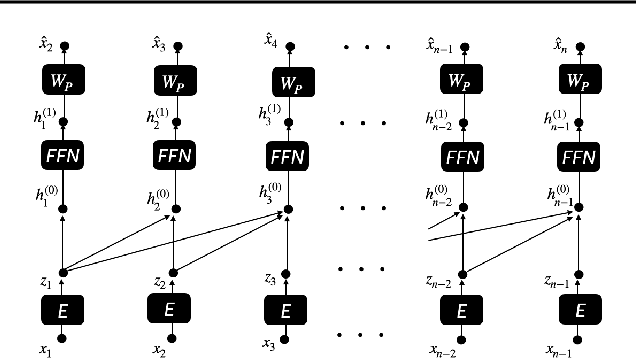
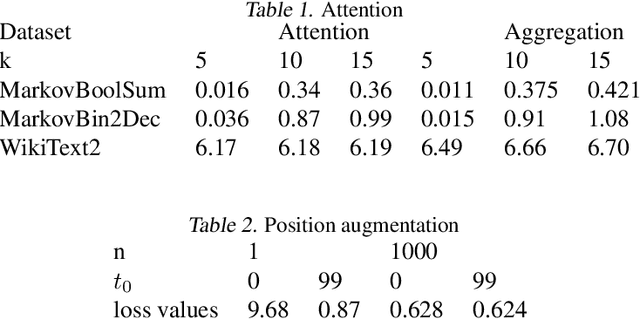
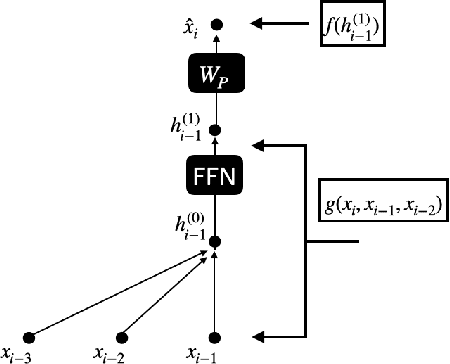
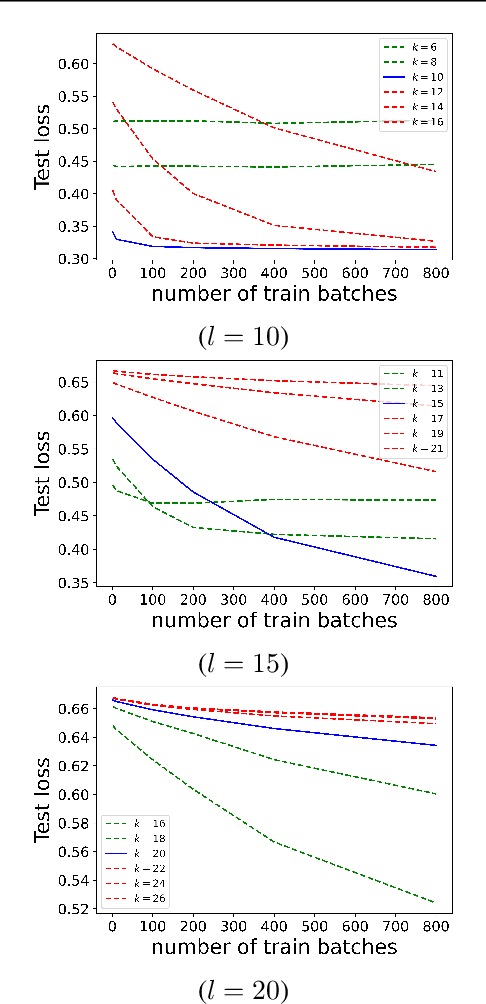
We find limits to the Transformer architecture for language modeling and show it has a universal prediction property in an information-theoretic sense. We further analyze performance in non-asymptotic data regimes to understand the role of various components of the Transformer architecture, especially in the context of data-efficient training. We validate our theoretical analysis with experiments on both synthetic and real datasets.
* Neural Compression Workshop (ICML 2023)
View paper on