 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer with Depth-Wise LSTM
Paper and Code
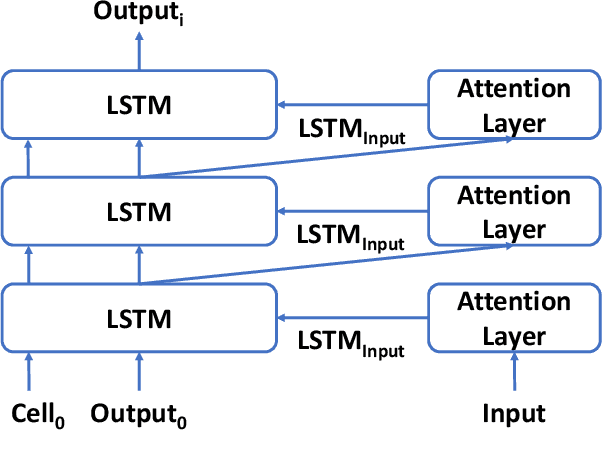
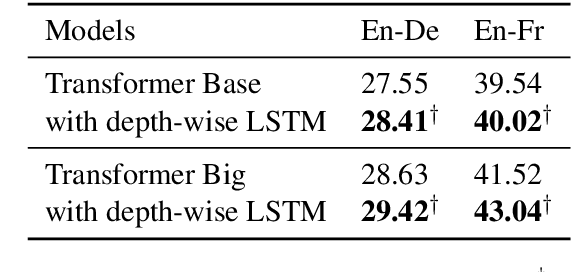
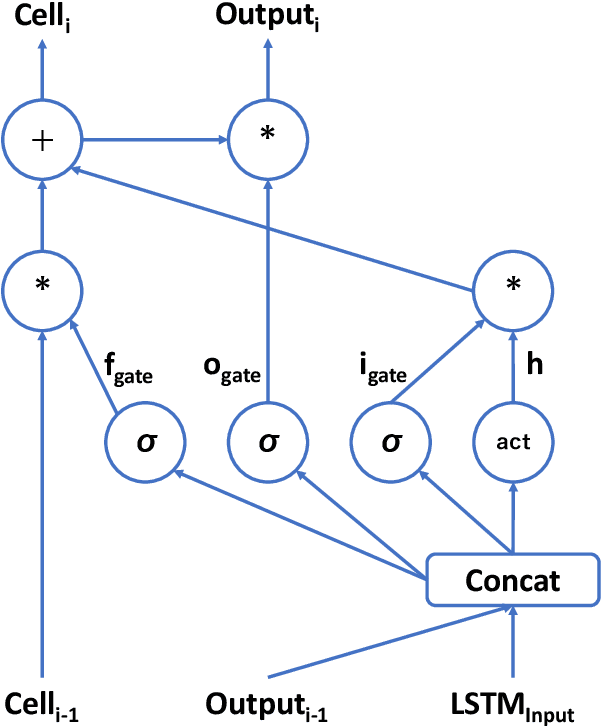

Increasing the depth of models allows neural models to model complicated functions but may also lead to optimization issues. The Transformer translation model employs the residual connection to ensure its convergence. In this paper, we suggest that the residual connection has its drawbacks, and propose to train Transformers with the depth-wise LSTM which regards outputs of layers as steps in time series instead of residual connections, under the motivation that the vanishing gradient problem suffered by deep networks is the same as recurrent networks applied to long sequences, while LSTM (Hochreiter and Schmidhuber, 1997) has been proven of good capability in capturing long-distance relationship, and its design may alleviate some drawbacks of residual connections while ensuring the convergence. We integrate the computation of multi-head attention networks and feed-forward networks with the depth-wise LSTM for the Transformer, which shows how to utilize the depth-wise LSTM like the residual connection. Our experiment with the 6-layer Transformer shows that our approach can bring about significant BLEU improvements in both WMT 14 English-German and English-French tasks, and our deep Transformer experiment demonstrates the effectiveness of the depth-wise LSTM on the convergence of deep Transformers. Additionally, we propose to measure the impacts of the layer's non-linearity on the performance by distilling the analyzing layer of the trained model into a linear transformation and observing the performance degradation with the replacement. Our analysis results support the more efficient use of per-layer non-linearity with depth-wise LSTM than with residual connections.