 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based Text Classification on Unified Bangla Multi-class Emotion Corpus
Paper and Code

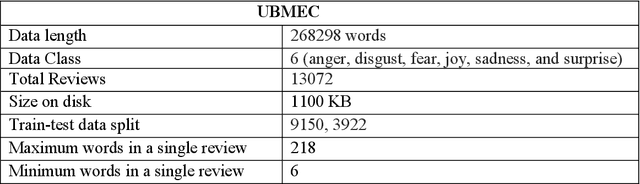
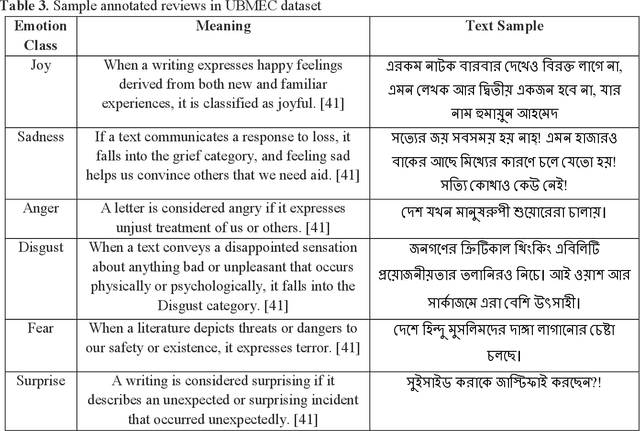
Because of its importance in studying people's thoughts on various Web 2.0 services, emotion classification (EC) is an important undertaking. Existing research, on the other hand, is mostly focused on the English language, with little work on low-resource languages. Though sentiment analysis, particularly the EC in English, has received a lot of attention in recent years, little study has been done in the context of Bangla, one of the world's most widely spoken languages. We propose a complete set of approaches for identifying and extracting emotions from Bangla texts in this research. We provide a Bangla emotion classifier for six classes (anger, disgust, fear, joy, sadness, and surprise) from Bangla words, using transformer-based models which exhibit phenomenal results in recent days, especially for high resource languages. The "Unified Bangla Multi-class Emotion Corpus (UBMEC)" is used to assess the performance of our models. UBMEC was created by combining two previously released manually labeled datasets of Bangla comments on 6-emotion classes with fresh manually tagged Bangla comments created by us. The corpus dataset and code we used in this work is publicly available.