 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Spatio-Temporal Association of Apple Fruitlets
Paper and Code
Mar 05, 2025
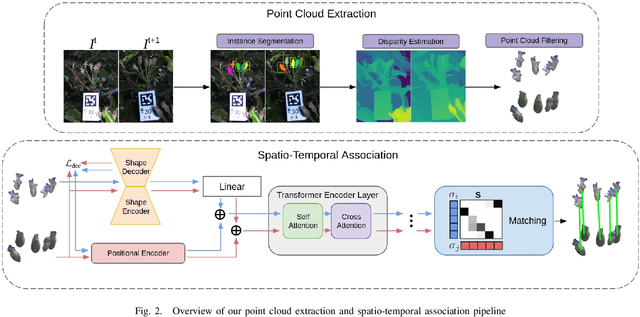
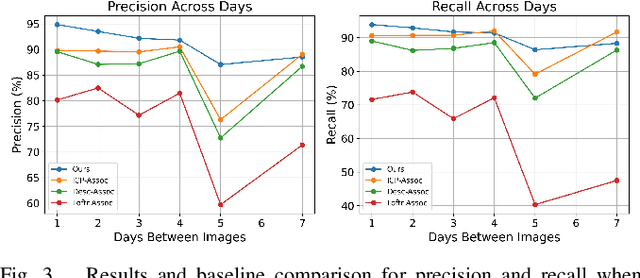
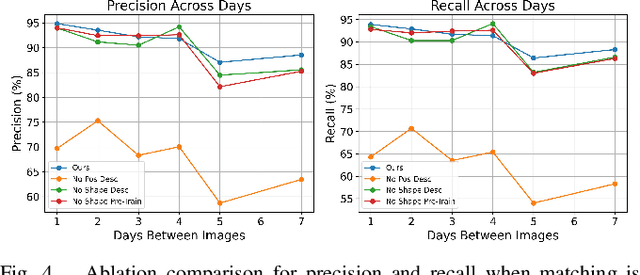
In this paper, we present a transformer-based method to spatio-temporally associate apple fruitlets in stereo-images collected on different days and from different camera poses. State-of-the-art association methods in agriculture are dedicated towards matching larger crops using either high-resolution point clouds or temporally stable features, which are both difficult to obtain for smaller fruit in the field. To address these challenges, we propose a transformer-based architecture that encodes the shape and position of each fruitlet, and propagates and refines these features through a series of transformer encoder layers with alternating self and cross-attention. We demonstrate that our method is able to achieve an F1-score of 92.4% on data collected in a commercial apple orchard and outperforms all baselines and ablations.