 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer based Multilingual document Embedding model
Paper and Code
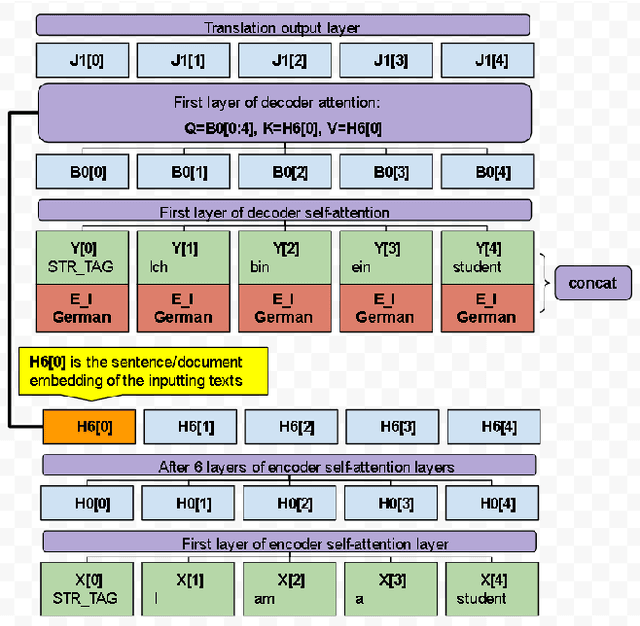


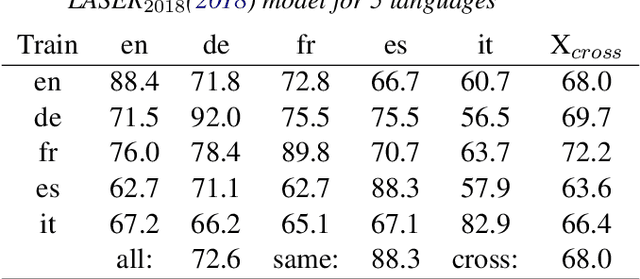
One of the current state-of-the-art multilingual document embedding model LASER is based on the bidirectional LSTM neural machine translation model. This paper presents a transformer-based sentence/document embedding model, T-LASER, which makes three significant improvements. Firstly, the BiLSTM layers is replaced by the attention-based transformer layers, which is more capable of learning sequential patterns in longer texts. Secondly, due to the absence of recurrence, T-LASER enables faster parallel computations in the encoder to generate the text embedding. Thirdly, we augment the NMT translation loss function with an additional novel distance constraint loss. This distance constraint loss would further bring the embeddings of parallel sentences close together in the vector space; we call the T-LASER model trained with distance constraint, cT-LASER. Our cT-LASER model significantly outperforms both BiLSTM-based LASER and the simpler transformer-based T-LASER.