 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferability and Hardness of Supervised Classification Tasks
Paper and Code
Aug 21, 2019
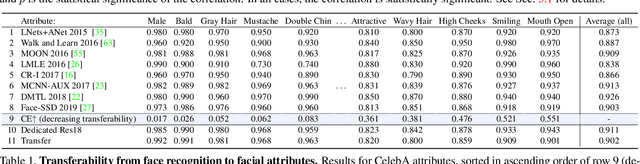
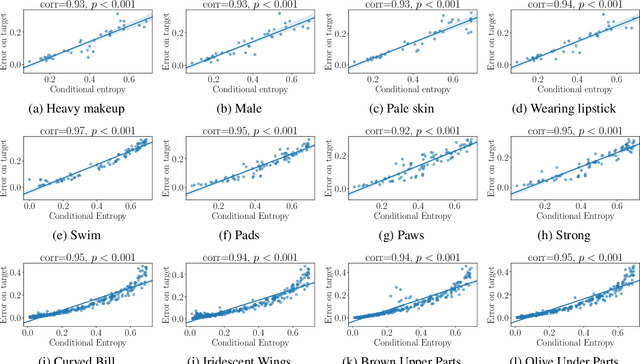
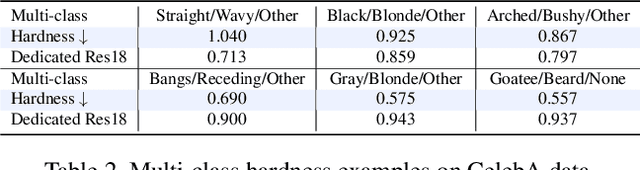
We propose a novel approach for estimating the difficulty and transferability of supervised classification tasks. Unlike previous work, our approach is solution agnostic and does not require or assume trained models. Instead, we estimate these values using an information theoretic approach: treating training labels as random variables and exploring their statistics. When transferring from a source to a target task, we consider the conditional entropy between two such variables (i.e., label assignments of the two tasks). We show analytically and empirically that this value is related to the loss of the transferred model. We further show how to use this value to estimate task hardness. We test our claims extensively on three large scale data sets -- CelebA (40 tasks), Animals with Attributes 2 (85 tasks), and Caltech-UCSD Birds 200 (312 tasks) -- together representing 437 classification tasks. We provide results showing that our hardness and transferability estimates are strongly correlated with empirical hardness and transferability. As a case study, we transfer a learned face recognition model to CelebA attribute classification tasks, showing state of the art accuracy for tasks estimated to be highly transferable.