 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer learning for self-supervised, blind-spot seismic denoising
Paper and Code
Sep 25, 2022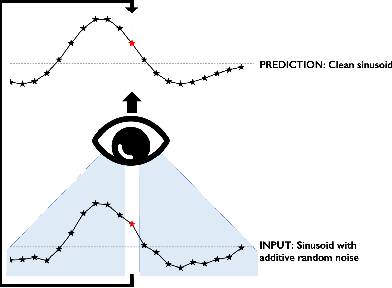
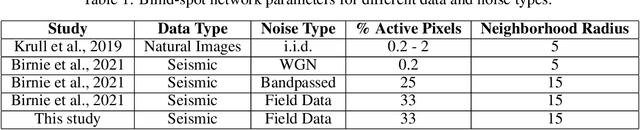


Noise in seismic data arises from numerous sources and is continually evolving. The use of supervised deep learning procedures for denoising of seismic datasets often results in poor performance: this is due to the lack of noise-free field data to act as training targets and the large difference in characteristics between synthetic and field datasets. Self-supervised, blind-spot networks typically overcome these limitation by training directly on the raw, noisy data. However, such networks often rely on a random noise assumption, and their denoising capabilities quickly decrease in the presence of even minimally-correlated noise. Extending from blind-spots to blind-masks can efficiently suppress coherent noise along a specific direction, but it cannot adapt to the ever-changing properties of noise. To preempt the network's ability to predict the signal and reduce its opportunity to learn the noise properties, we propose an initial, supervised training of the network on a frugally-generated synthetic dataset prior to fine-tuning in a self-supervised manner on the field dataset of interest. Considering the change in peak signal-to-noise ratio, as well as the volume of noise reduced and signal leakage observed, we illustrate the clear benefit in initialising the self-supervised network with the weights from a supervised base-training. This is further supported by a test on a field dataset where the fine-tuned network strikes the best balance between signal preservation and noise reduction. Finally, the use of the unrealistic, frugally-generated synthetic dataset for the supervised base-training includes a number of benefits: minimal prior geological knowledge is required, substantially reduced computational cost for the dataset generation, and a reduced requirement of re-training the network should recording conditions change, to name a few.