 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransductive Multi-label Zero-shot Learning
Paper and Code
Mar 26, 2015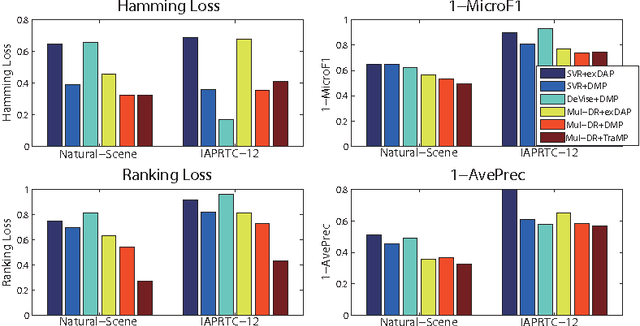


Zero-shot learning has received increasing interest as a means to alleviate the often prohibitive expense of annotating training data for large scale recognition problems. These methods have achieved great success via learning intermediate semantic representations in the form of attributes and more recently, semantic word vectors. However, they have thus far been constrained to the single-label case, in contrast to the growing popularity and importance of more realistic multi-label data. In this paper, for the first time, we investigate and formalise a general framework for multi-label zero-shot learning, addressing the unique challenge therein: how to exploit multi-label correlation at test time with no training data for those classes? In particular, we propose (1) a multi-output deep regression model to project an image into a semantic word space, which explicitly exploits the correlations in the intermediate semantic layer of word vectors; (2) a novel zero-shot learning algorithm for multi-label data that exploits the unique compositionality property of semantic word vector representations; and (3) a transductive learning strategy to enable the regression model learned from seen classes to generalise well to unseen classes. Our zero-shot learning experiments on a number of standard multi-label datasets demonstrate that our method outperforms a variety of baselines.