 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Robust Zero-Shot Voice Conversion Models with Self-supervised Features
Paper and Code
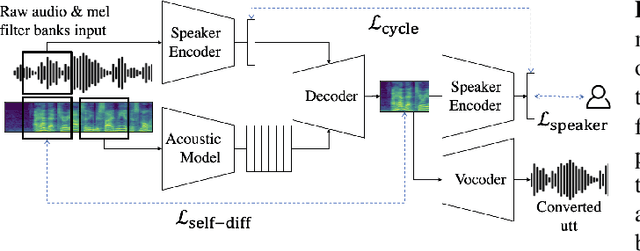
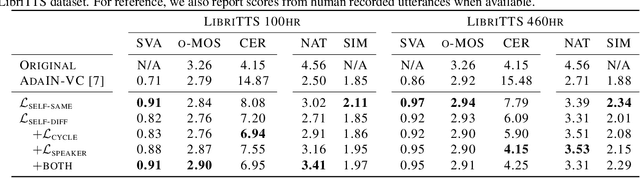
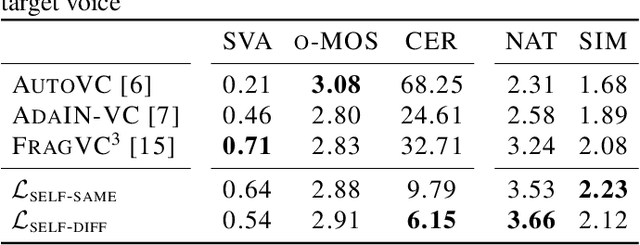
Unsupervised Zero-Shot Voice Conversion (VC) aims to modify the speaker characteristic of an utterance to match an unseen target speaker without relying on parallel training data. Recently, self-supervised learning of speech representation has been shown to produce useful linguistic units without using transcripts, which can be directly passed to a VC model. In this paper, we showed that high-quality audio samples can be achieved by using a length resampling decoder, which enables the VC model to work in conjunction with different linguistic feature extractors and vocoders without requiring them to operate on the same sequence length. We showed that our method can outperform many baselines on the VCTK dataset. Without modifying the architecture, we further demonstrated that a) using pairs of different audio segments from the same speaker, b) adding a cycle consistency loss, and c) adding a speaker classification loss can help to learn a better speaker embedding. Our model trained on LibriTTS using these techniques achieves the best performance, producing audio samples transferred well to the target speaker's voice, while preserving the linguistic content that is comparable with actual human utterances in terms of Character Error Rate.