 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining dataset and dictionary sizes matter in BERT models: the case of Baltic languages
Paper and Code

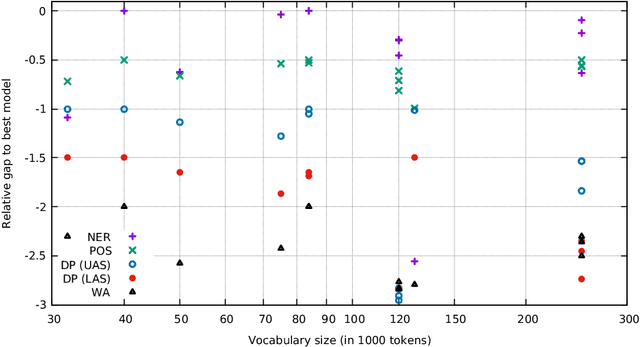
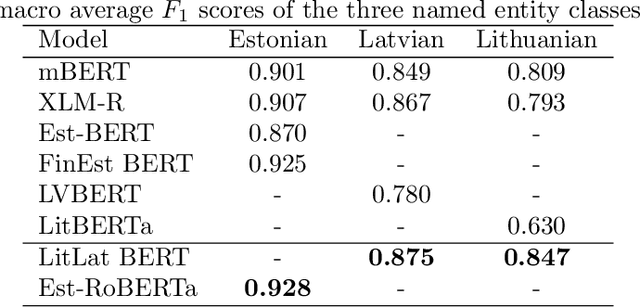
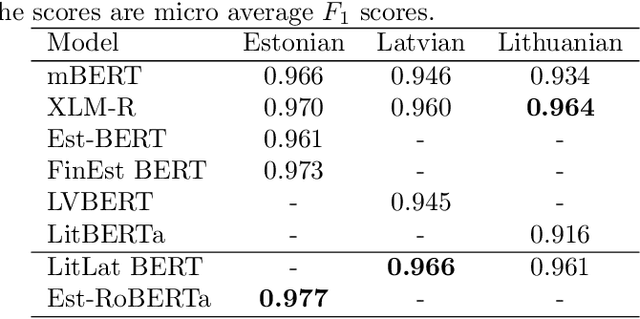
Large pretrained masked language models have become state-of-the-art solutions for many NLP problems. While studies have shown that monolingual models produce better results than multilingual models, the training datasets must be sufficiently large. We trained a trilingual LitLat BERT-like model for Lithuanian, Latvian, and English, and a monolingual Est-RoBERTa model for Estonian. We evaluate their performance on four downstream tasks: named entity recognition, dependency parsing, part-of-speech tagging, and word analogy. To analyze the importance of focusing on a single language and the importance of a large training set, we compare created models with existing monolingual and multilingual BERT models for Estonian, Latvian, and Lithuanian. The results show that the newly created LitLat BERT and Est-RoBERTa models improve the results of existing models on all tested tasks in most situations.