 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Classifiers that are Universally Robust to All Label Noise Levels
Paper and Code
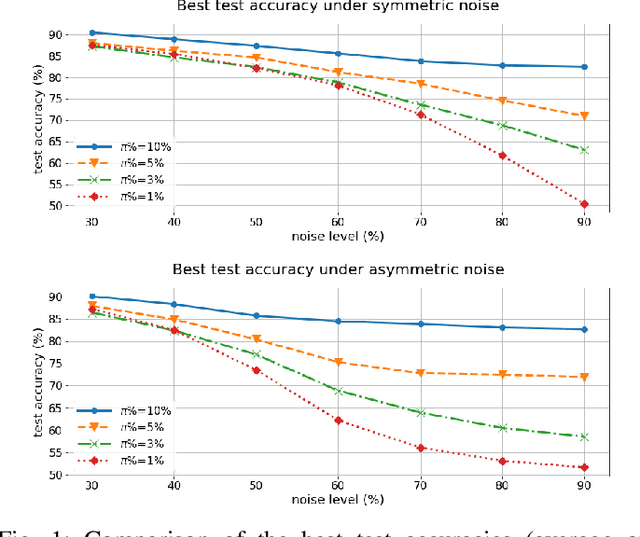
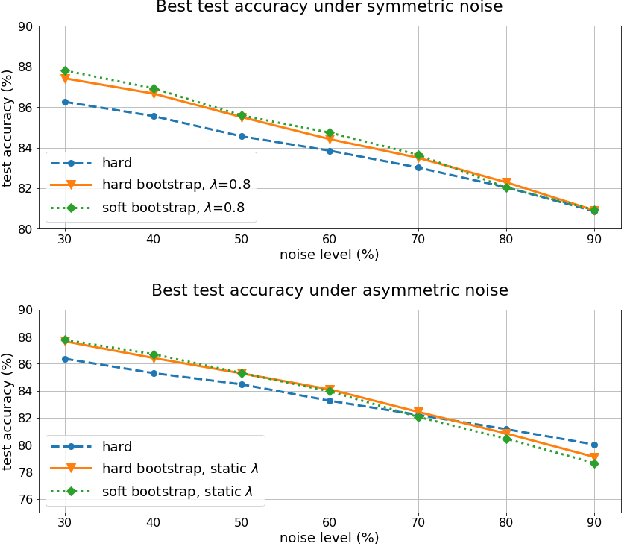
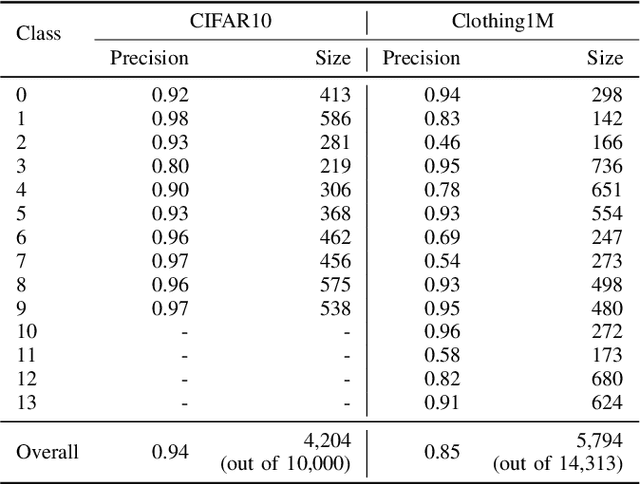
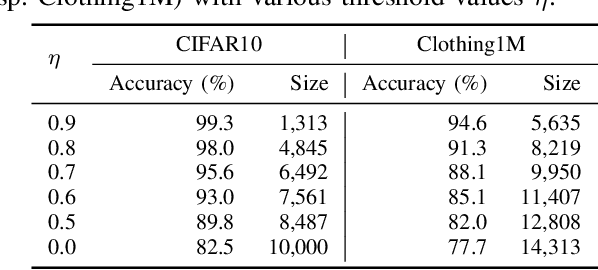
For classification tasks, deep neural networks are prone to overfitting in the presence of label noise. Although existing methods are able to alleviate this problem at low noise levels, they encounter significant performance reduction at high noise levels, or even at medium noise levels when the label noise is asymmetric. To train classifiers that are universally robust to all noise levels, and that are not sensitive to any variation in the noise model, we propose a distillation-based framework that incorporates a new subcategory of Positive-Unlabeled learning. In particular, we shall assume that a small subset of any given noisy dataset is known to have correct labels, which we treat as "positive", while the remaining noisy subset is treated as "unlabeled". Our framework consists of the following two components: (1) We shall generate, via iterative updates, an augmented clean subset with additional reliable "positive" samples filtered from "unlabeled" samples; (2) We shall train a teacher model on this larger augmented clean set. With the guidance of the teacher model, we then train a student model on the whole dataset. Experiments were conducted on the CIFAR-10 dataset with synthetic label noise at multiple noise levels for both symmetric and asymmetric noise. The results show that our framework generally outperforms at medium to high noise levels. We also evaluated our framework on Clothing1M, a real-world noisy dataset, and we achieved 2.94% improvement in accuracy over existing state-of-the-art methods.