 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTR-MOT: Multi-Object Tracking by Reference
Paper and Code
Mar 30, 2022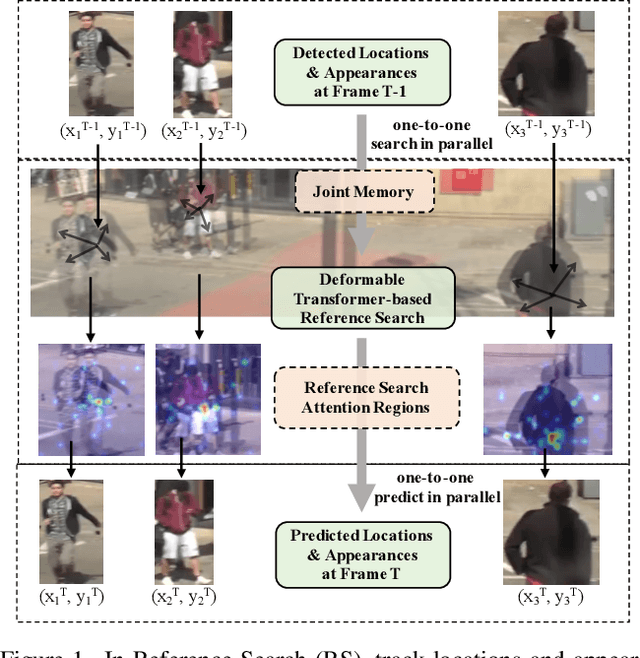
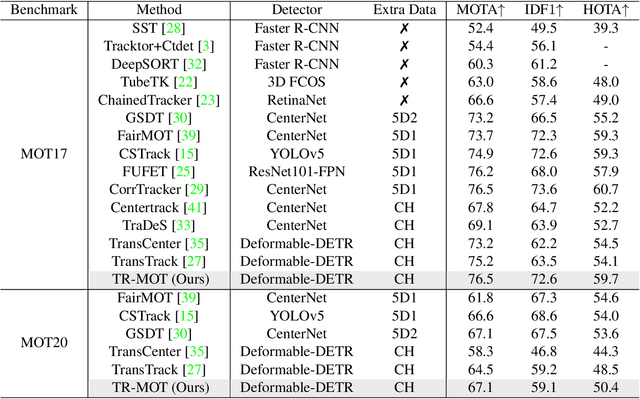
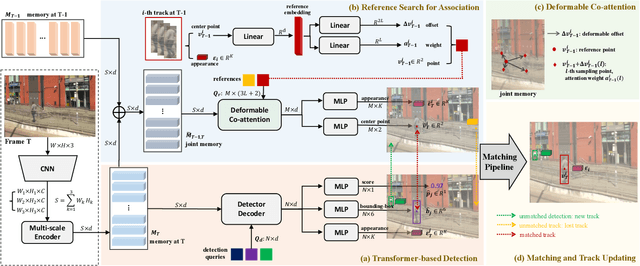
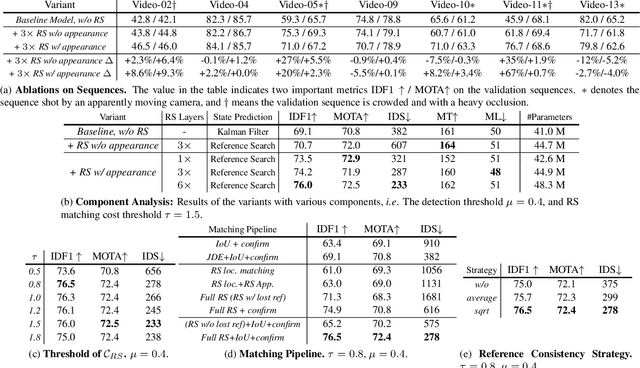
Multi-object Tracking (MOT) generally can be split into two sub-tasks, i.e., detection and association. Many previous methods follow the tracking by detection paradigm, which first obtain detections at each frame and then associate them between adjacent frames. Though with an impressive performance by utilizing a strong detector, it will degrade their detection and association performance under scenes with many occlusions and large motion if not using temporal information. In this paper, we propose a novel Reference Search (RS) module to provide a more reliable association based on the deformable transformer structure, which is natural to learn the feature alignment for each object among frames. RS takes previous detected results as references to aggregate the corresponding features from the combined features of the adjacent frames and makes a one-to-one track state prediction for each reference in parallel. Therefore, RS can attain a reliable association coping with unexpected motions by leveraging visual temporal features while maintaining the strong detection performance by decoupling from the detector. Our RS module can also be compatible with the structure of the other tracking by detection frameworks. Furthermore, we propose a joint training strategy and an effective matching pipeline for our online MOT framework with the RS module. Our method achieves competitive results on MOT17 and MOT20 datasets.