 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTP-GMOT: Tracking Generic Multiple Object by Textual Prompt with Motion-Appearance Cost (MAC) SORT
Paper and Code
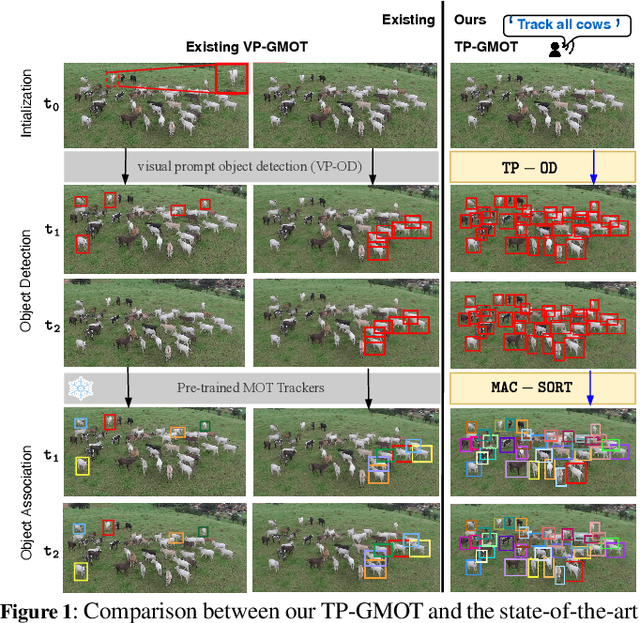
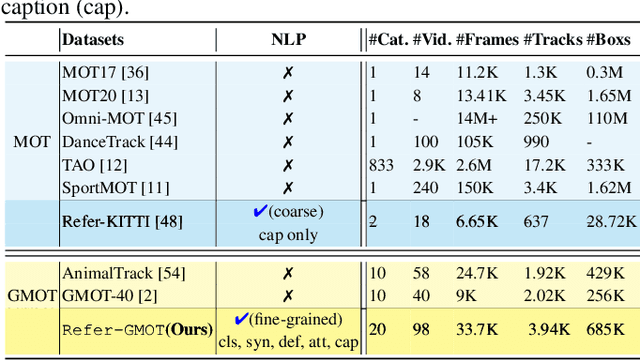

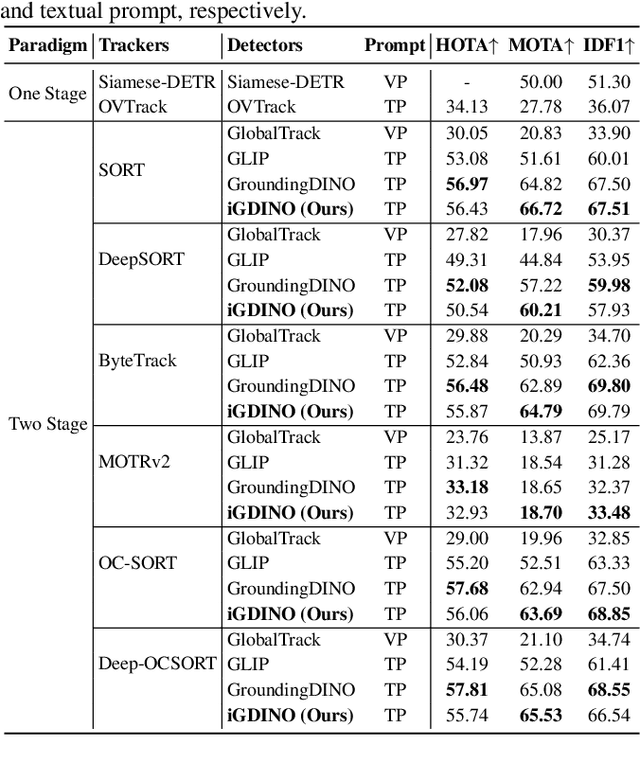
While Multi-Object Tracking (MOT) has made substantial advancements, it is limited by heavy reliance on prior knowledge and limited to predefined categories. In contrast, Generic Multiple Object Tracking (GMOT), tracking multiple objects with similar appearance, requires less prior information about the targets but faces challenges with variants like viewpoint, lighting, occlusion, and resolution. Our contributions commence with the introduction of the \textbf{\text{Refer-GMOT dataset}} a collection of videos, each accompanied by fine-grained textual descriptions of their attributes. Subsequently, we introduce a novel text prompt-based open-vocabulary GMOT framework, called \textbf{\text{TP-GMOT}}, which can track never-seen object categories with zero training examples. Within \text{TP-GMOT} framework, we introduce two novel components: (i) {\textbf{\text{TP-OD}}, an object detection by a textual prompt}, for accurately detecting unseen objects with specific characteristics. (ii) Motion-Appearance Cost SORT \textbf{\text{MAC-SORT}}, a novel object association approach that adeptly integrates motion and appearance-based matching strategies to tackle the complex task of tracking multiple generic objects with high similarity. Our contributions are benchmarked on the \text{Refer-GMOT} dataset for GMOT task. Additionally, to assess the generalizability of the proposed \text{TP-GMOT} framework and the effectiveness of \text{MAC-SORT} tracker, we conduct ablation studies on the DanceTrack and MOT20 datasets for the MOT task. Our dataset, code, and models will be publicly available at: https://fsoft-aic.github.io/TP-GMOT