 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding the Universality of Transformers for Next-Token Prediction
Paper and Code
Oct 03, 2024
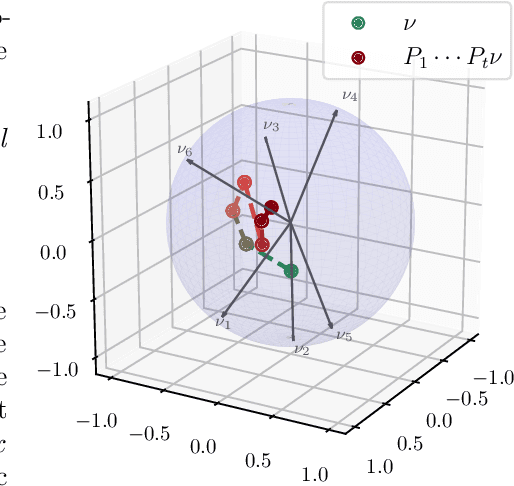

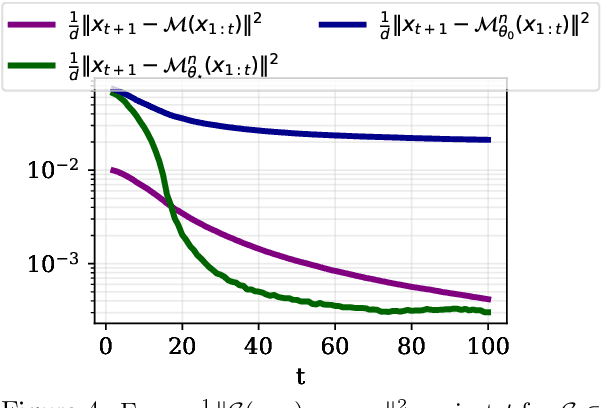
Causal Transformers are trained to predict the next token for a given context. While it is widely accepted that self-attention is crucial for encoding the causal structure of sequences, the precise underlying mechanism behind this in-context autoregressive learning ability remains unclear. In this paper, we take a step towards understanding this phenomenon by studying the approximation ability of Transformers for next-token prediction. Specifically, we explore the capacity of causal Transformers to predict the next token $x_{t+1}$ given an autoregressive sequence $(x_1, \dots, x_t)$ as a prompt, where $ x_{t+1} = f(x_t) $, and $ f $ is a context-dependent function that varies with each sequence. On the theoretical side, we focus on specific instances, namely when $ f $ is linear or when $ (x_t)_{t \geq 1} $ is periodic. We explicitly construct a Transformer (with linear, exponential, or softmax attention) that learns the mapping $f$ in-context through a causal kernel descent method. The causal kernel descent method we propose provably estimates $x_{t+1} $ based solely on past and current observations $ (x_1, \dots, x_t) $, with connections to the Kaczmarz algorithm in Hilbert spaces. We present experimental results that validate our theoretical findings and suggest their applicability to more general mappings $f$.