 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding the Generalization of Graph Neural Networks
Paper and Code
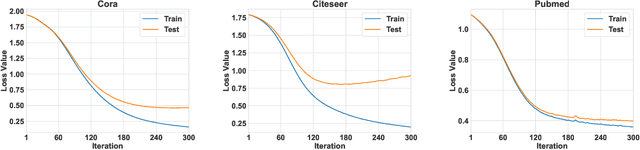
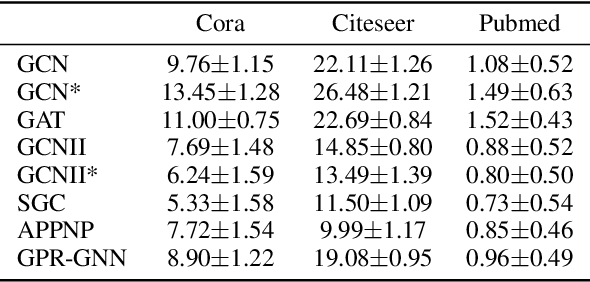
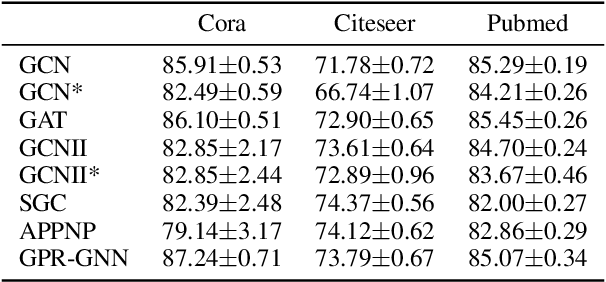
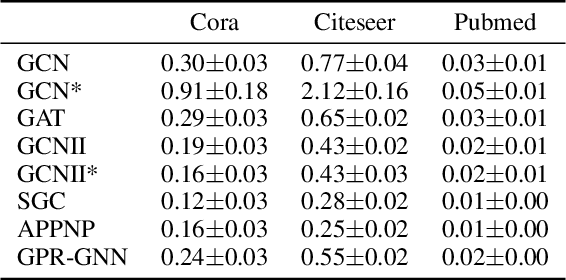
Graph neural networks (GNNs) are the most widely adopted model in graph-structured data oriented learning and representation. Despite their extraordinary success in real-world applications, understanding their working mechanism by theory is still on primary stage. In this paper, we move towards this goal from the perspective of generalization. To be specific, we first establish high probability bounds of generalization gap and gradients in transductive learning with consideration of stochastic optimization. After that, we provide high probability bounds of generalization gap for popular GNNs. The theoretical results reveal the architecture specific factors affecting the generalization gap. Experimental results on benchmark datasets show the consistency between theoretical results and empirical evidence. Our results provide new insights in understanding the generalization of GNNs.