 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Trustworthy Healthcare AI: Attention-Based Feature Learning for COVID-19 Screening With Chest Radiography
Paper and Code
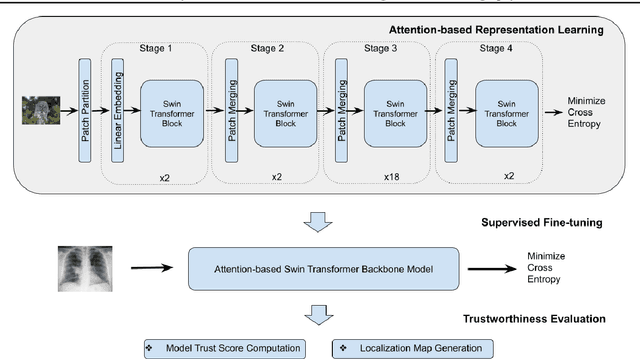

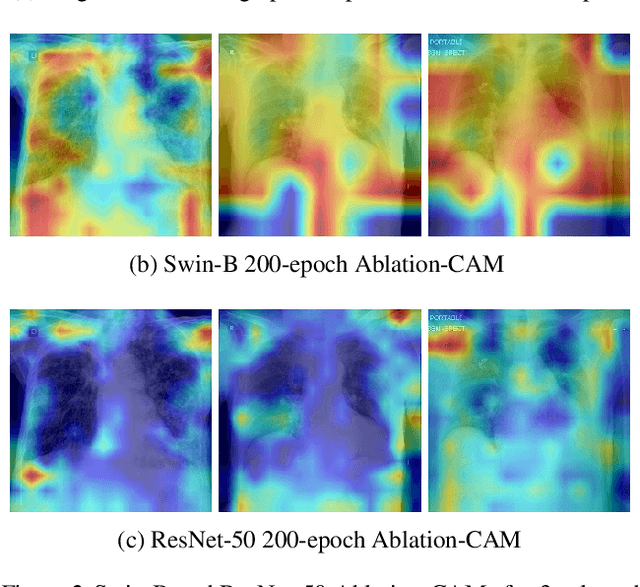
Building AI models with trustworthiness is important especially in regulated areas such as healthcare. In tackling COVID-19, previous work uses convolutional neural networks as the backbone architecture, which has shown to be prone to over-caution and overconfidence in making decisions, rendering them less trustworthy -- a crucial flaw in the context of medical imaging. In this study, we propose a feature learning approach using Vision Transformers, which use an attention-based mechanism, and examine the representation learning capability of Transformers as a new backbone architecture for medical imaging. Through the task of classifying COVID-19 chest radiographs, we investigate into whether generalization capabilities benefit solely from Vision Transformers' architectural advances. Quantitative and qualitative evaluations are conducted on the trustworthiness of the models, through the use of "trust score" computation and a visual explainability technique. We conclude that the attention-based feature learning approach is promising in building trustworthy deep learning models for healthcare.