 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Single Stage Weakly Supervised Semantic Segmentation
Paper and Code
Jun 28, 2021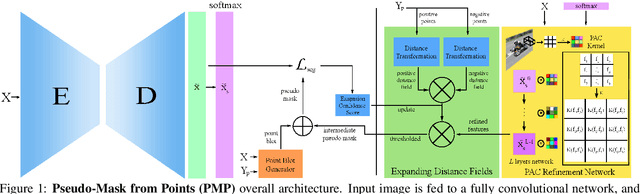


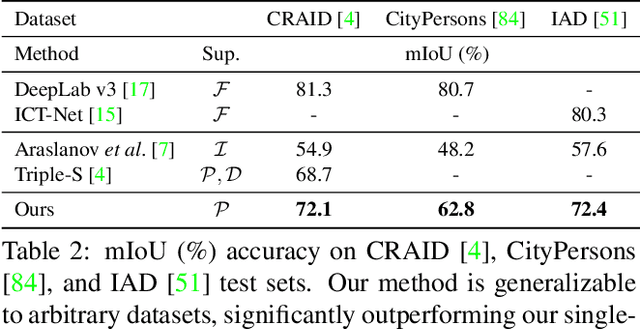
The costly process of obtaining semantic segmentation labels has driven research towards weakly supervised semantic segmentation (WSSS) methods, using only image-level, point, or box labels. The lack of dense scene representation requires methods to increase complexity to obtain additional semantic information about the scene, often done through multiple stages of training and refinement. Current state-of-the-art (SOTA) models leverage image-level labels to produce class activation maps (CAMs) which go through multiple stages of refinement before they are thresholded to make pseudo-masks for supervision. The multi-stage approach is computationally expensive, and dependency on image-level labels for CAMs generation lacks generalizability to more complex scenes. In contrary, our method offers a single-stage approach generalizable to arbitrary dataset, that is trainable from scratch, without any dependency on pre-trained backbones, classification, or separate refinement tasks. We utilize point annotations to generate reliable, on-the-fly pseudo-masks through refined and filtered features. While our method requires point annotations that are only slightly more expensive than image-level annotations, we are to demonstrate SOTA performance on benchmark datasets (PascalVOC 2012), as well as significantly outperform other SOTA WSSS methods on recent real-world datasets (CRAID, CityPersons, IAD).