 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sharper First-Order Adversary with Quantized Gradients
Paper and Code
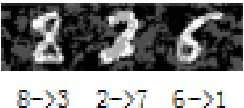



Despite the huge success of Deep Neural Networks (DNNs) in a wide spectrum of machine learning and data mining tasks, recent research shows that this powerful tool is susceptible to maliciously crafted adversarial examples. Up until now, adversarial training has been the most successful defense against adversarial attacks. To increase adversarial robustness, a DNN can be trained with a combination of benign and adversarial examples generated by first-order methods. However, in state-of-the-art first-order attacks, adversarial examples with sign gradients retain the sign information of each gradient component but discard the relative magnitude between components. In this work, we replace sign gradients with quantized gradients. Gradient quantization not only preserves the sign information, but also keeps the relative magnitude between components. Experiments show white-box first-order attacks with quantized gradients outperform their variants with sign gradients on multiple datasets. Notably, our BLOB\_QG attack achieves an accuracy of $88.32\%$ on the secret MNIST model from the MNIST Challenge and it outperforms all other methods on the leaderboard of white-box attacks.