Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Deep Learning with Ensemble Networks and Noisy Layers
Paper and Code
Jul 03, 2020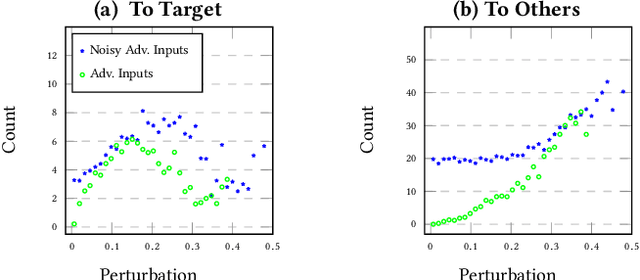
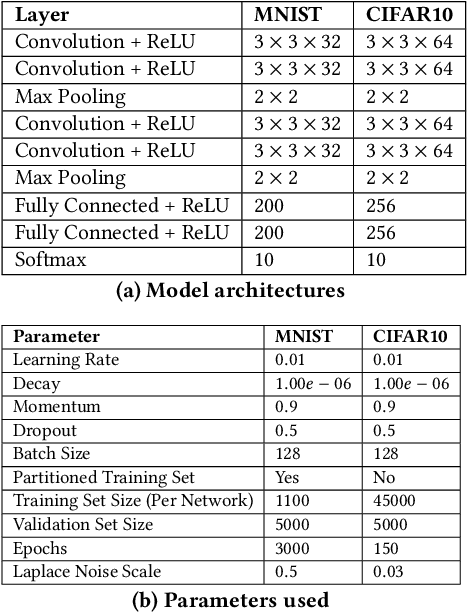
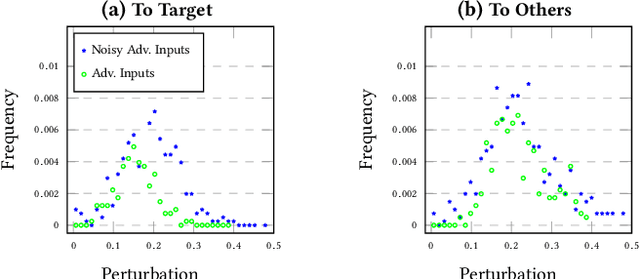
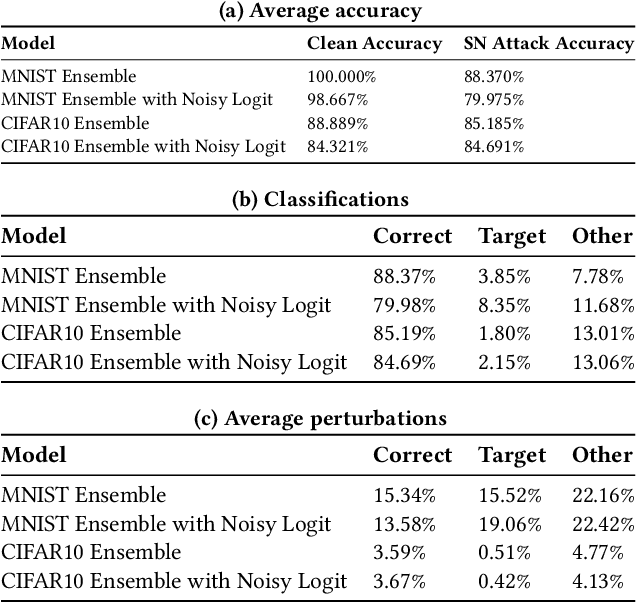
In this paper we provide an approach for deep learning that protects against adversarial examples in image classification-type networks. The approach relies on two mechanisms:1) a mechanism that increases robustness at the expense of accuracy, and, 2) a mechanism that improves accuracy but does not always increase robustness. We show that an approach combining the two mechanisms can provide protection against adversarial examples while retaining accuracy. We formulate potential attacks on our approach and provide experimental results to demonstrate the effectiveness of our approach.
View paper on