 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Realistic Semi-Supervised Learning
Paper and Code
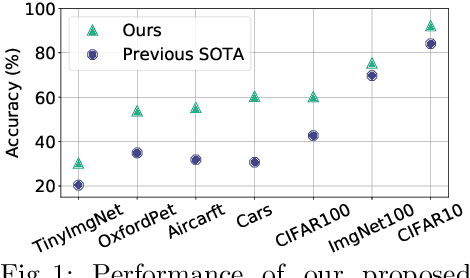
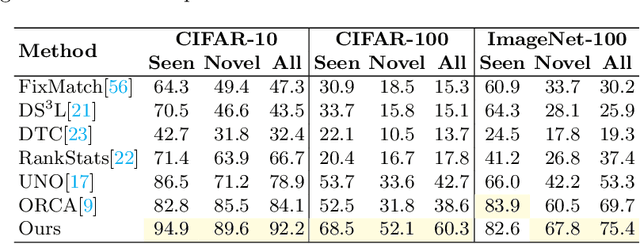


Deep learning is pushing the state-of-the-art in many computer vision applications. However, it relies on large annotated data repositories, and capturing the unconstrained nature of the real-world data is yet to be solved. Semi-supervised learning (SSL) complements the annotated training data with a large corpus of unlabeled data to reduce annotation cost. The standard SSL approach assumes unlabeled data are from the same distribution as annotated data. Recently, ORCA [9] introduce a more realistic SSL problem, called open-world SSL, by assuming that the unannotated data might contain samples from unknown classes. This work proposes a novel approach to tackle SSL in open-world setting, where we simultaneously learn to classify known and unknown classes. At the core of our method, we utilize sample uncertainty and incorporate prior knowledge about class distribution to generate reliable pseudo-labels for unlabeled data belonging to both known and unknown classes. Our extensive experimentation showcases the effectiveness of our approach on several benchmark datasets, where it substantially outperforms the existing state-of-the-art on seven diverse datasets including CIFAR-100 (17.6%), ImageNet-100 (5.7%), and Tiny ImageNet (9.9%).