 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Optimal Statistical Watermarking
Paper and Code
Dec 13, 2023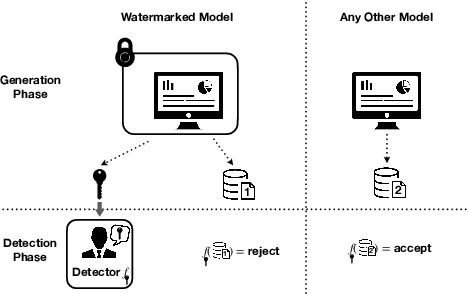
We study statistical watermarking by formulating it as a hypothesis testing problem, a general framework which subsumes all previous statistical watermarking methods. Key to our formulation is a coupling of the output tokens and the rejection region, realized by pseudo-random generators in practice, that allows non-trivial trade-off between the Type I error and Type II error. We characterize the Uniformly Most Powerful (UMP) watermark in this context. In the most common scenario where the output is a sequence of $n$ tokens, we establish matching upper and lower bounds on the number of i.i.d. tokens required to guarantee small Type I and Type II errors. Our rate scales as $\Theta(h^{-1} \log (1/h))$ with respect to the average entropy per token $h$ and thus greatly improves the $O(h^{-2})$ rate in the previous works. For scenarios where the detector lacks knowledge of the model's distribution, we introduce the concept of model-agnostic watermarking and establish the minimax bounds for the resultant increase in Type II error. Moreover, we formulate the robust watermarking problem where user is allowed to perform a class of perturbation on the generated texts, and characterize the optimal type II error of robust UMP tests via a linear programming problem. To the best of our knowledge, this is the first systematic statistical treatment on the watermarking problem with near-optimal rates in the i.i.d. setting, and might be of interest for future works.