 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Optimal Pricing of Demand Response -- A Nonparametric Constrained Policy Optimization Approach
Paper and Code
Jun 24, 2023
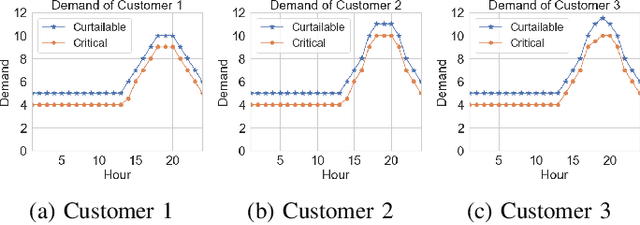
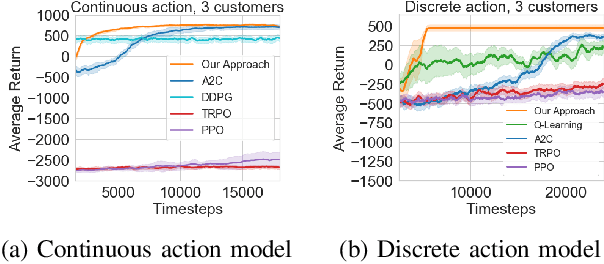
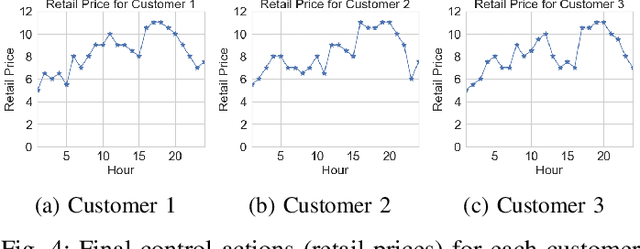
Demand response (DR) has been demonstrated to be an effective method for reducing peak load and mitigating uncertainties on both the supply and demand sides of the electricity market. One critical question for DR research is how to appropriately adjust electricity prices in order to shift electrical load from peak to off-peak hours. In recent years, reinforcement learning (RL) has been used to address the price-based DR problem because it is a model-free technique that does not necessitate the identification of models for end-use customers. However, the majority of RL methods cannot guarantee the stability and optimality of the learned pricing policy, which is undesirable in safety-critical power systems and may result in high customer bills. In this paper, we propose an innovative nonparametric constrained policy optimization approach that improves optimality while ensuring stability of the policy update, by removing the restrictive assumption on policy representation that the majority of the RL literature adopts: the policy must be parameterized or fall into a certain distribution class. We derive a closed-form expression of optimal policy update for each iteration and develop an efficient on-policy actor-critic algorithm to address the proposed constrained policy optimization problem. The experiments on two DR cases show the superior performance of our proposed nonparametric constrained policy optimization method compared with state-of-the-art RL algorithms.