 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Neural Theorem Proving at Scale
Paper and Code
Jul 21, 2018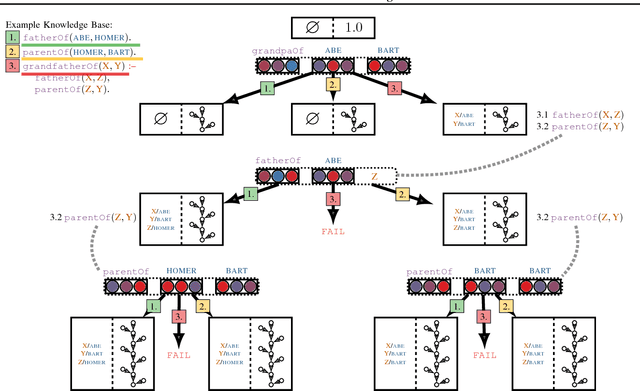
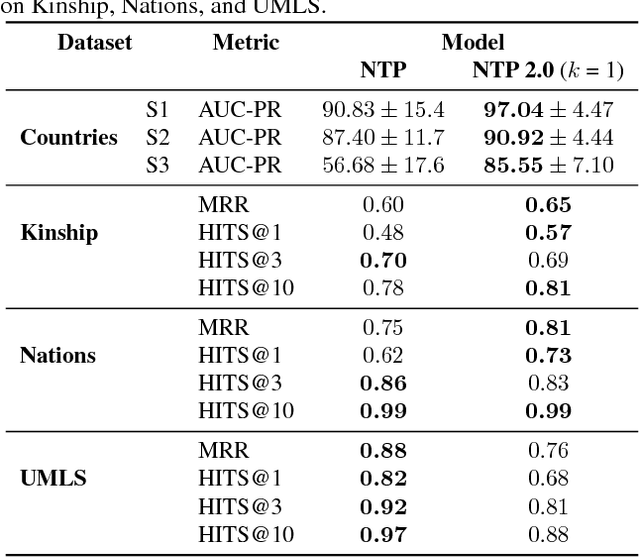
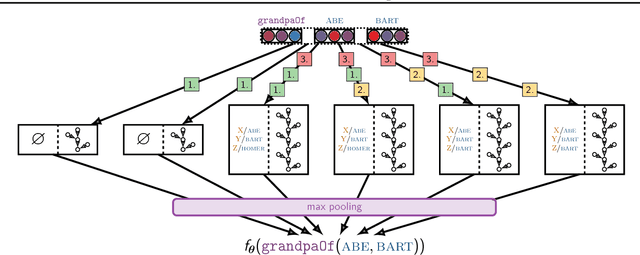

Neural models combining representation learning and reasoning in an end-to-end trainable manner are receiving increasing interest. However, their use is severely limited by their computational complexity, which renders them unusable on real world datasets. We focus on the Neural Theorem Prover (NTP) model proposed by Rockt{\"{a}}schel and Riedel (2017), a continuous relaxation of the Prolog backward chaining algorithm where unification between terms is replaced by the similarity between their embedding representations. For answering a given query, this model needs to consider all possible proof paths, and then aggregate results - this quickly becomes infeasible even for small Knowledge Bases (KBs). We observe that we can accurately approximate the inference process in this model by considering only proof paths associated with the highest proof scores. This enables inference and learning on previously impracticable KBs.